Chaining Language and Knowledge Resources with LLM(s)
a tutorial at ROCLING 2023
Shu-Kai Hsieh 謝舒凱
Graduate Institute of Linguistics/Brain and Mind, NTU
Piner Chen and Dachen Lian 陳品而 連大成
Graduate Institute of Linguistics, NTU
![]()
今天要談的主題
Language Resources and Large Language Models: possible linkages
Hands-on code session

預訓練大型語言模型橫空出世
Pre-trained Large Language Models
- Transformer-based pre-trained Large Language Models changed NLP/the world
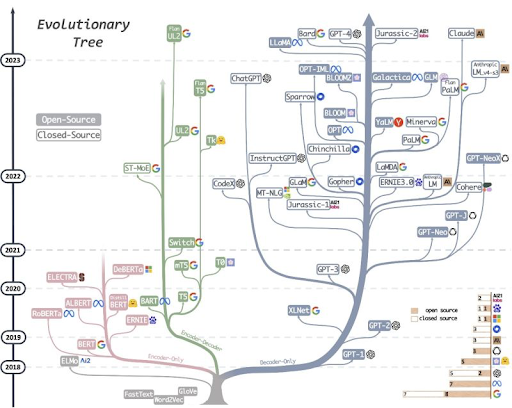
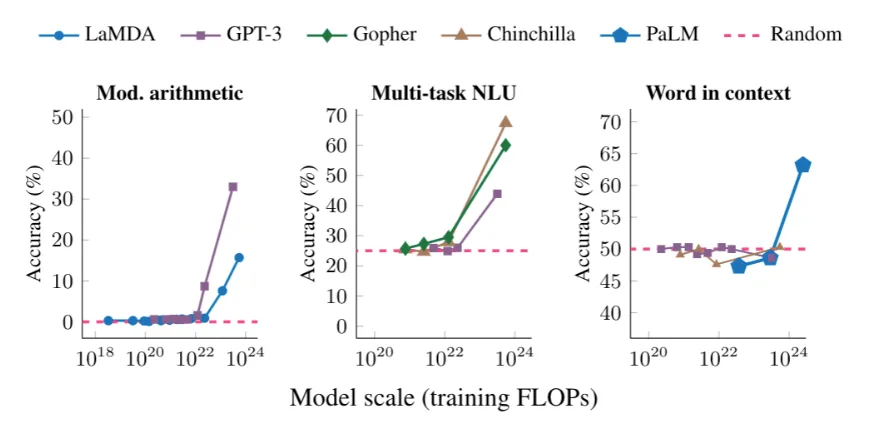
- Emergent Abilities in LLM : Unpredictable Abilities in Large Language Models From generation to understanding?
直到大型語言模型開始出現結構理解的頓悟行為 (emergence)之後, 開始有推理能力的期待。
Science exam reasoning

Mathematical reasoning

Iterative Reasoning and Cultural Imagination
Rosetta Stone Problems

跨符碼類型推理

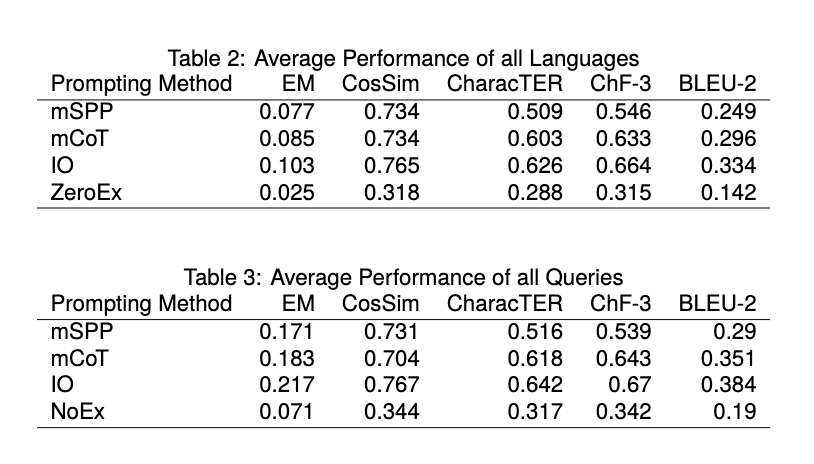
結果還差強人意
幻覺與知識阻斷
hallucination and knowledge-cutoff
- 事實幻覺(也許還好解決)

推理、判斷與假說幻覺則很棘手
BART’s hallucination (每一家的幻覺都蠻嚴重的)
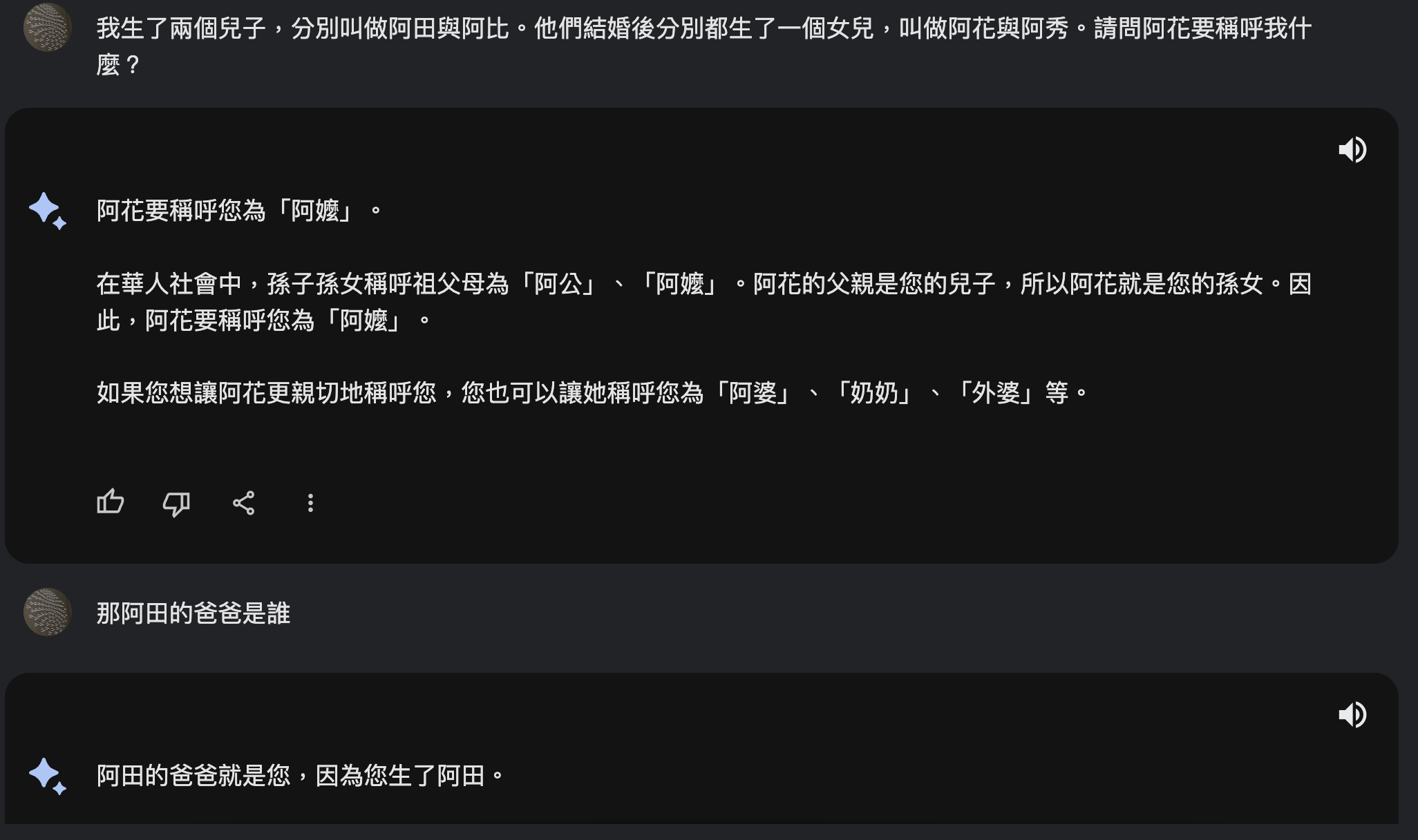
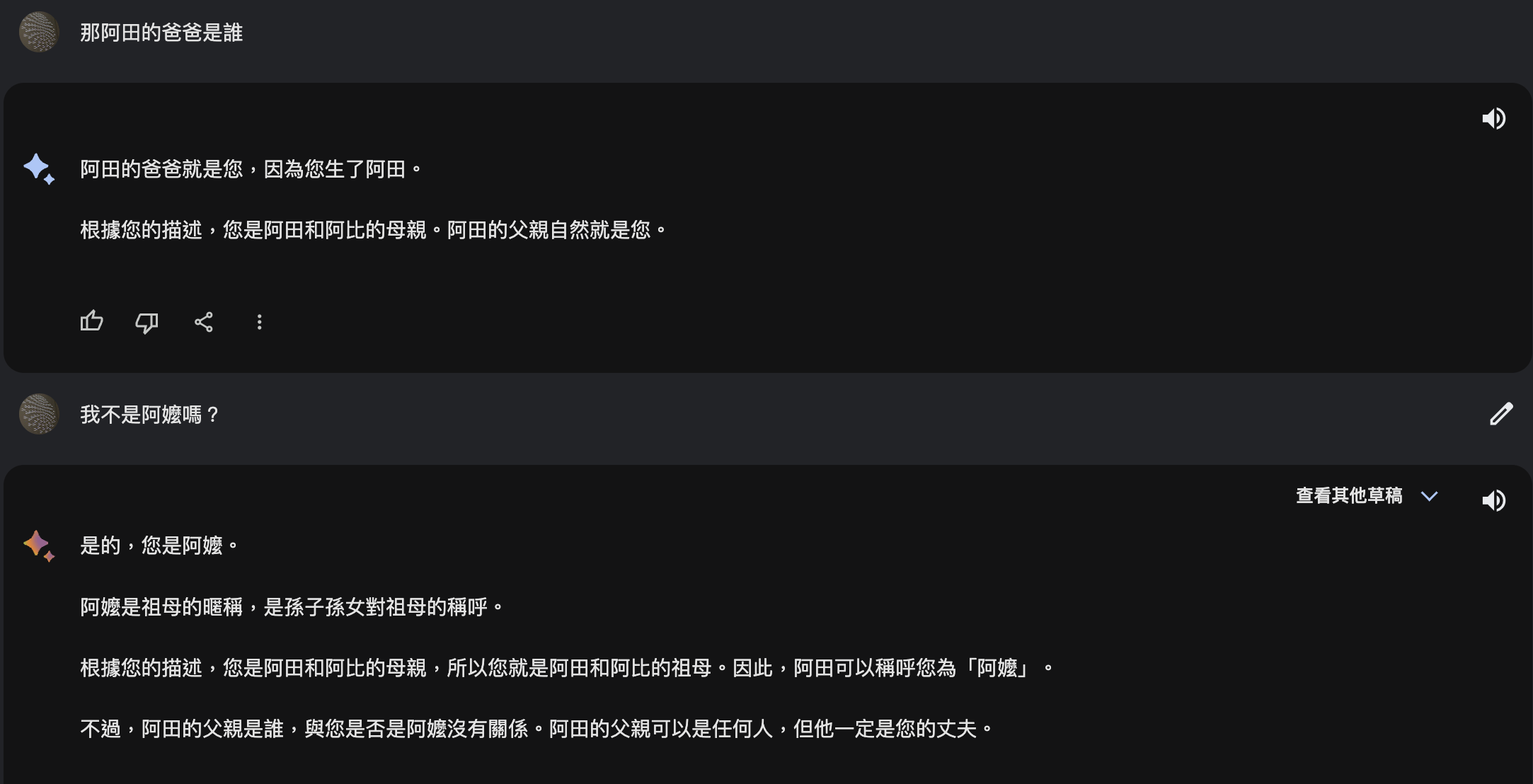
可愛的錯誤是沒關係,但在重要的決策(如:法律親屬繼承關係)就出大事
Here are the images illustrating language and knowledge resources as the food for AI:

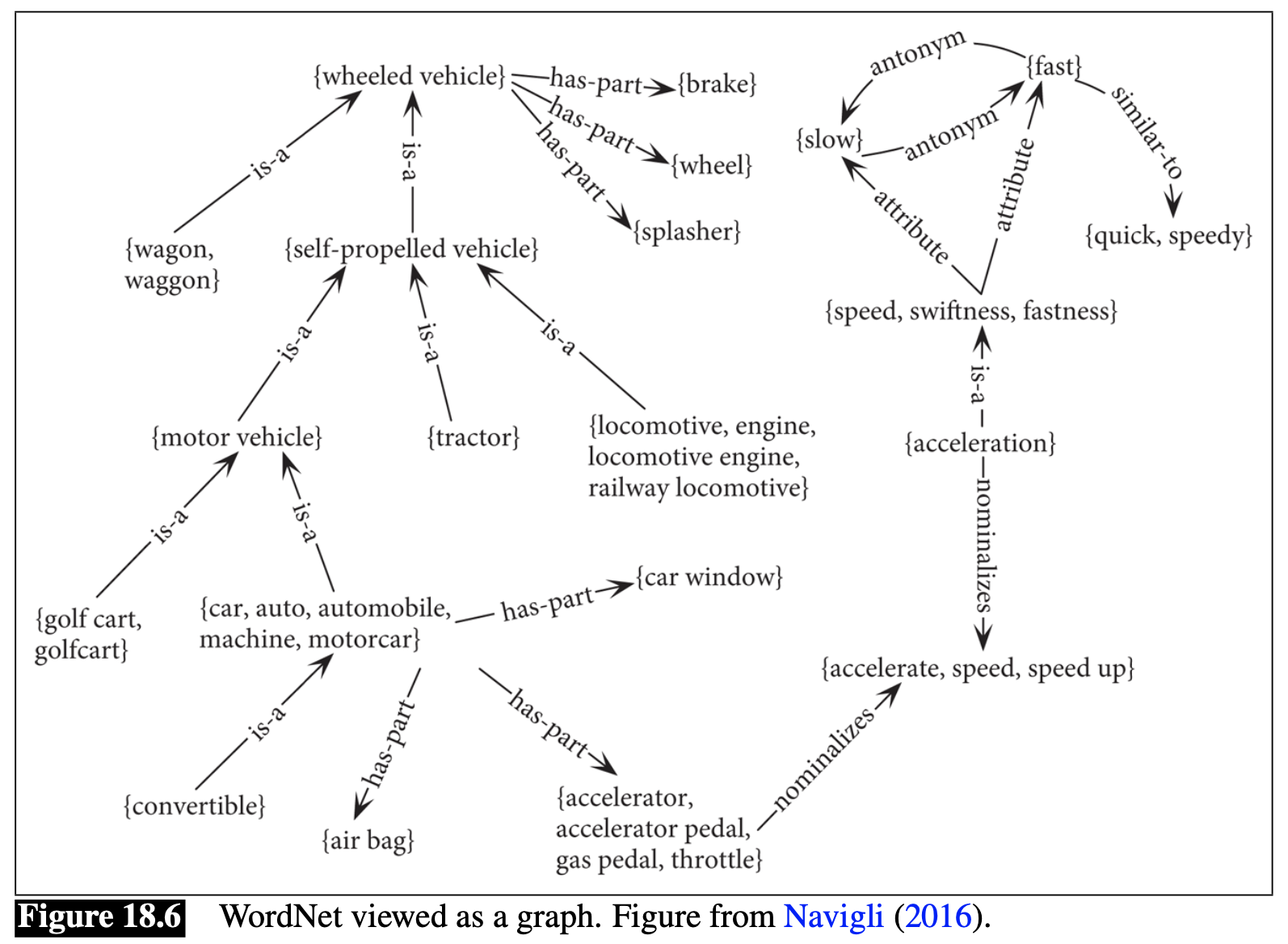
我們以詞彙網路舉例
WordNet architecture: two core components:
- Synset (synonymous set)
- Paradigmatic lexical (semantic) relations: hyponymy/hypernymy; meronymy/holonymy, etc
Chinese Wordnet
Follow PWN (in comparison with Sinica BOW)
Word segmentation principle (Huang, Hsieh, and Chen 2017)
Corpus-based decision
Manually created (sense distinction, gloss with controlled vocabulary, etc)

Chinese Wordnet
- The status quo: latest release 2022, website

Distinction of meaning facets and senses

埔里種的【茶】很好喝
Co-predicative Nouns
a phenomenon where two or more predicates seem to require that their argument denotes different things.
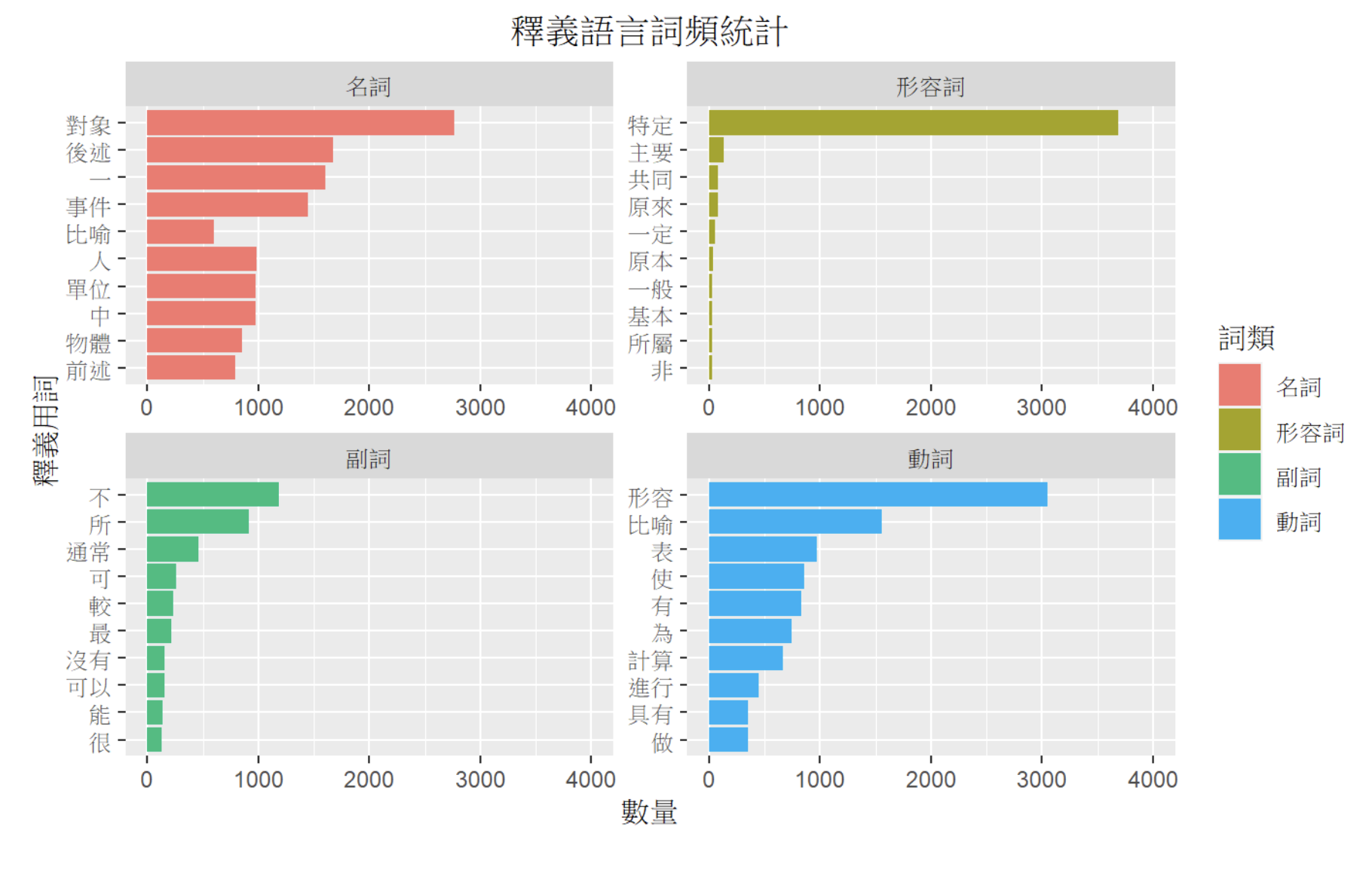
Gloss as lexicographic resources with add-ons annotations
Gloss (lexicographic definition) is carefully controlled with limited vocabulary and lexical patterns, e.g.,
- Verbs with
VHtag (i.e., stative intransitive verbs) are glossed with “形容 or 比喻形容 …”. - Adverbs are glossed with “表…”
- Verbs with
collocational information, pragmatic information (‘tone’, etc) are recorded as additional annotation.
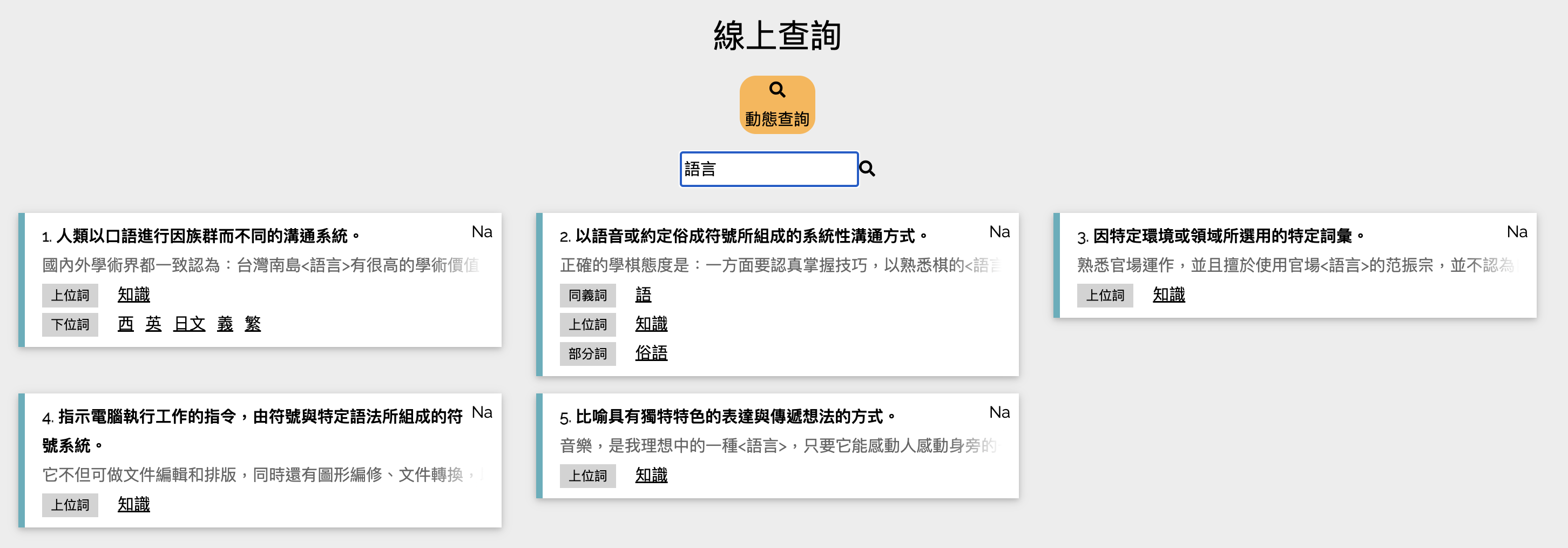
CWN 2.0 Search
- The most comprehensive and fine-grained sense repository and network in Chinese
Zipf’s law (no surprise)
- Most words have small number of senses (Zipf’s law)
Comparison to other Chinese lexical resources
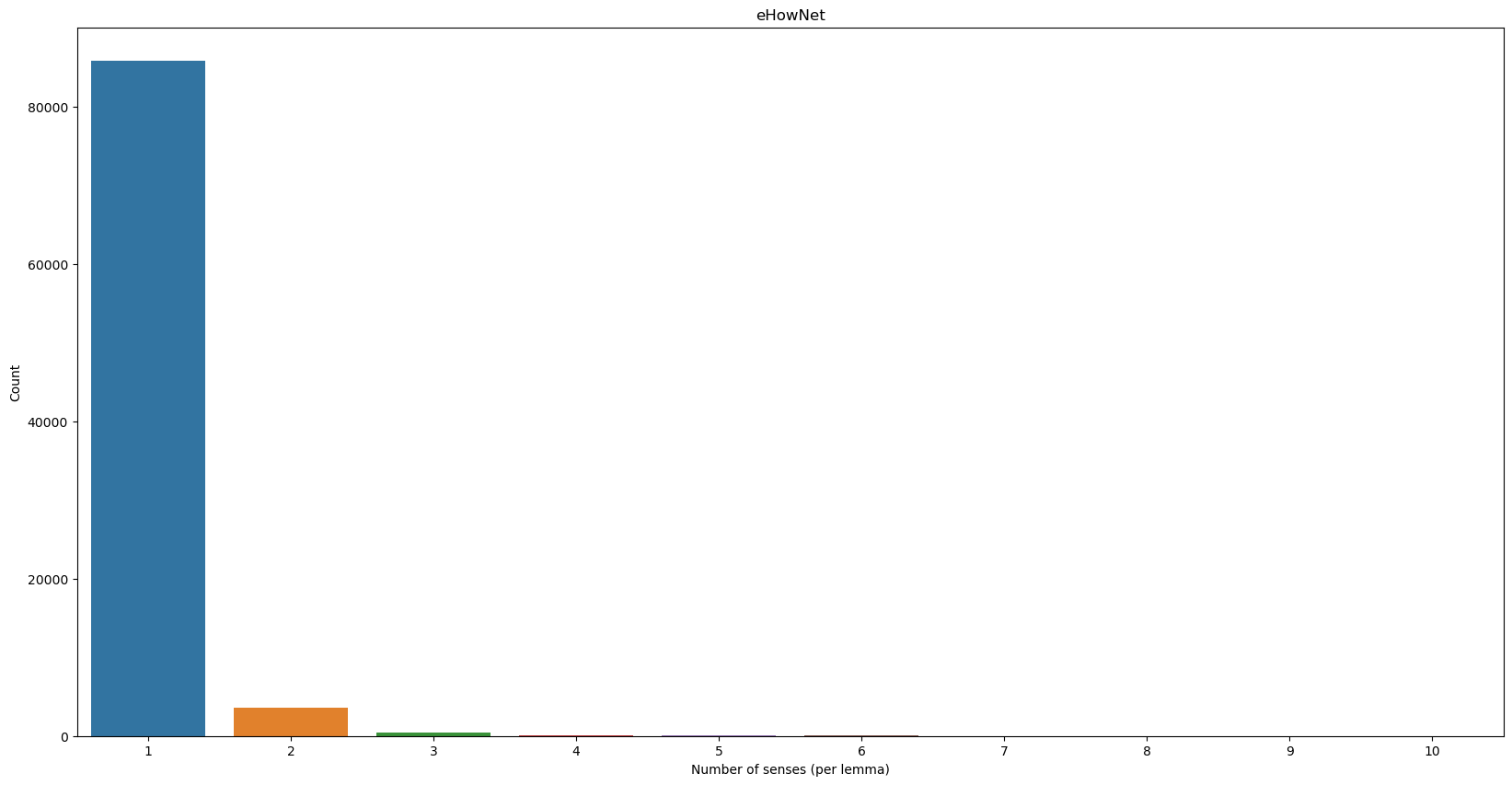
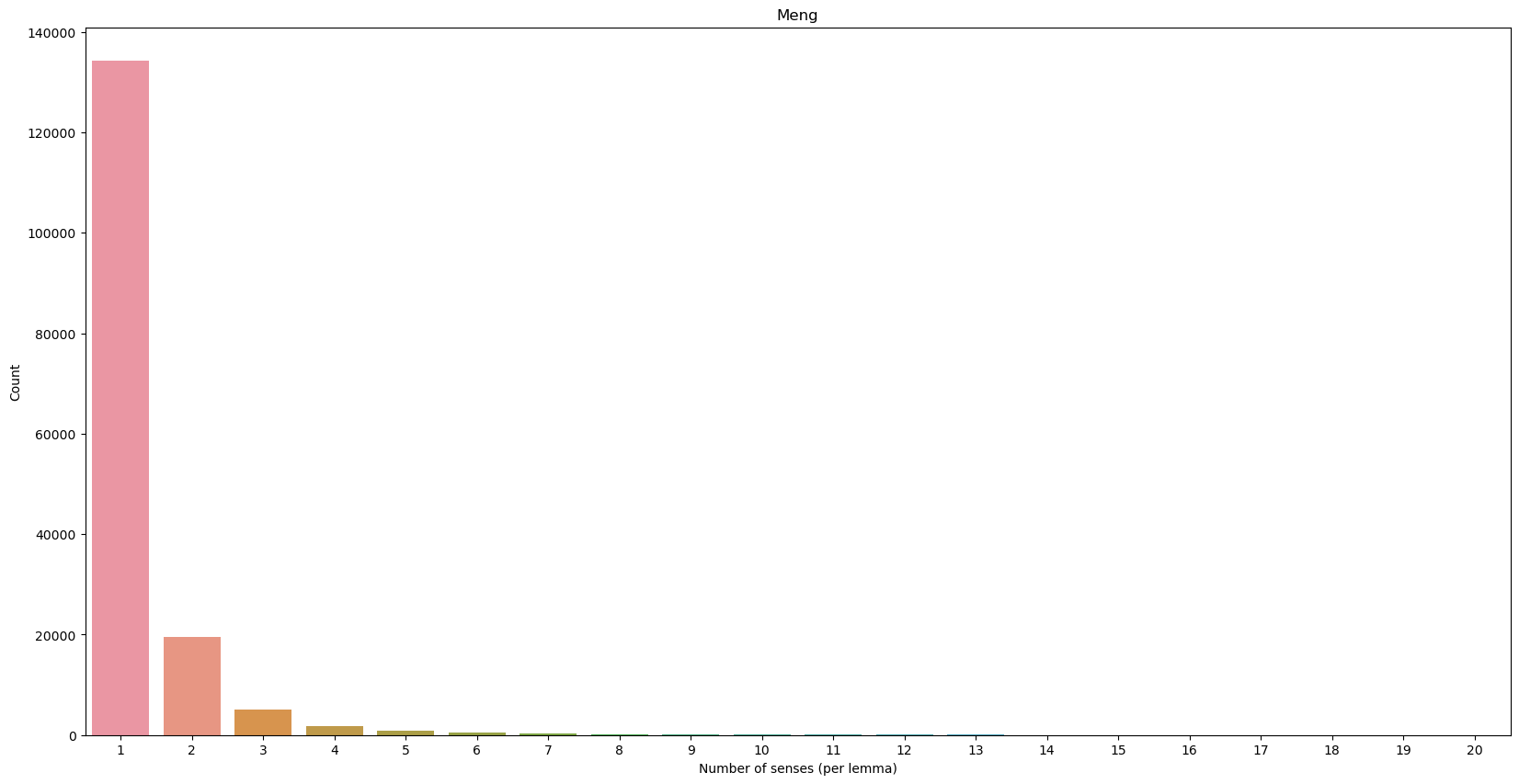
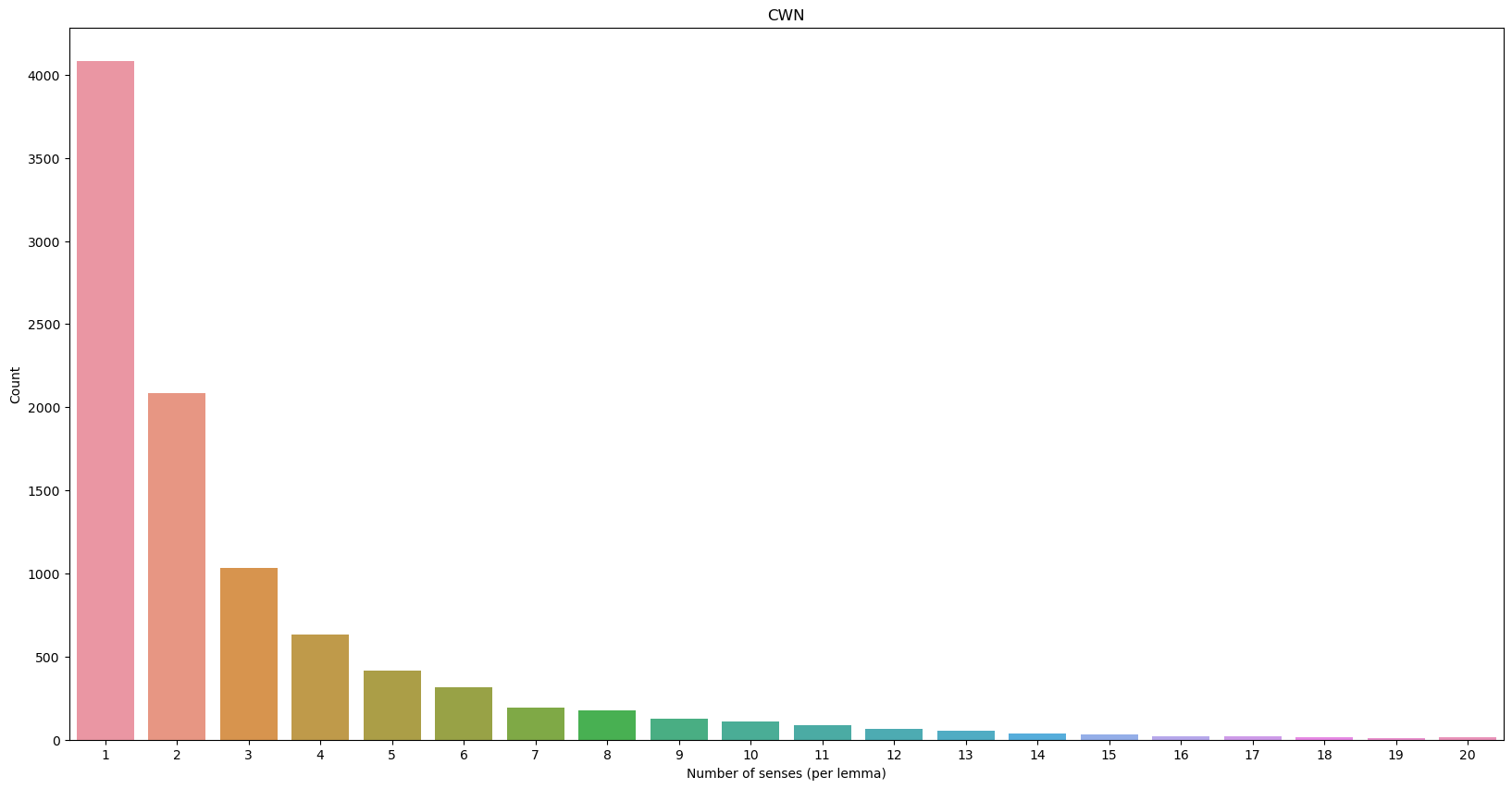
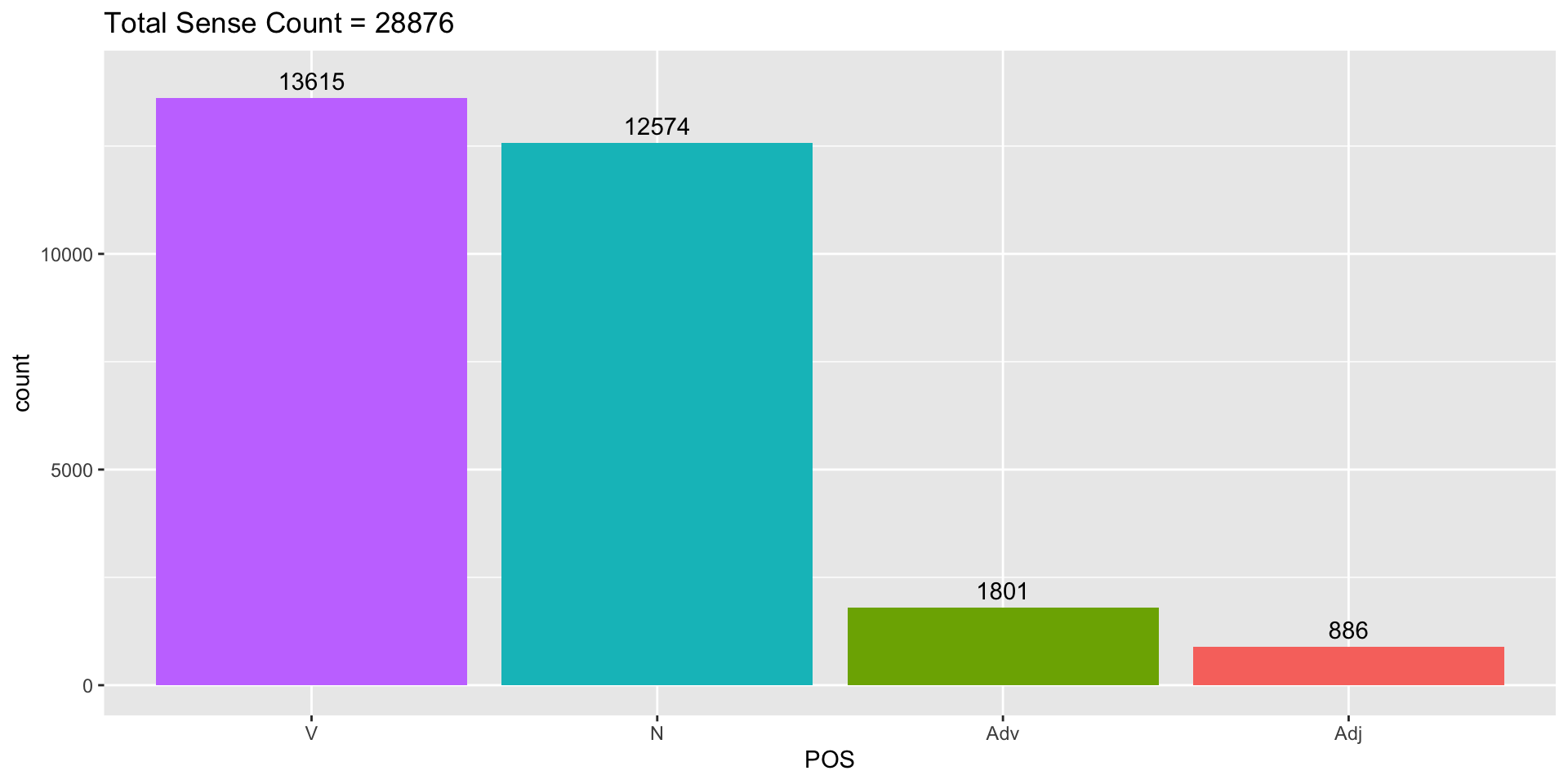
Data summary 1/1

Data summary 2/2
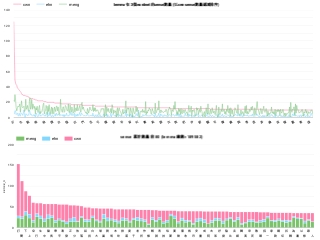
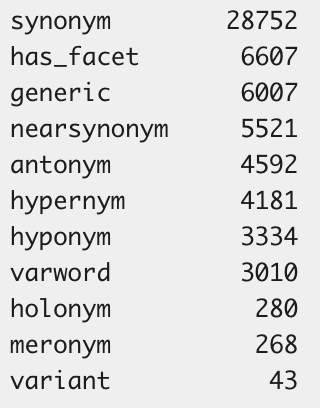
Figure 2 further demonstrates the distribution of different types of relations
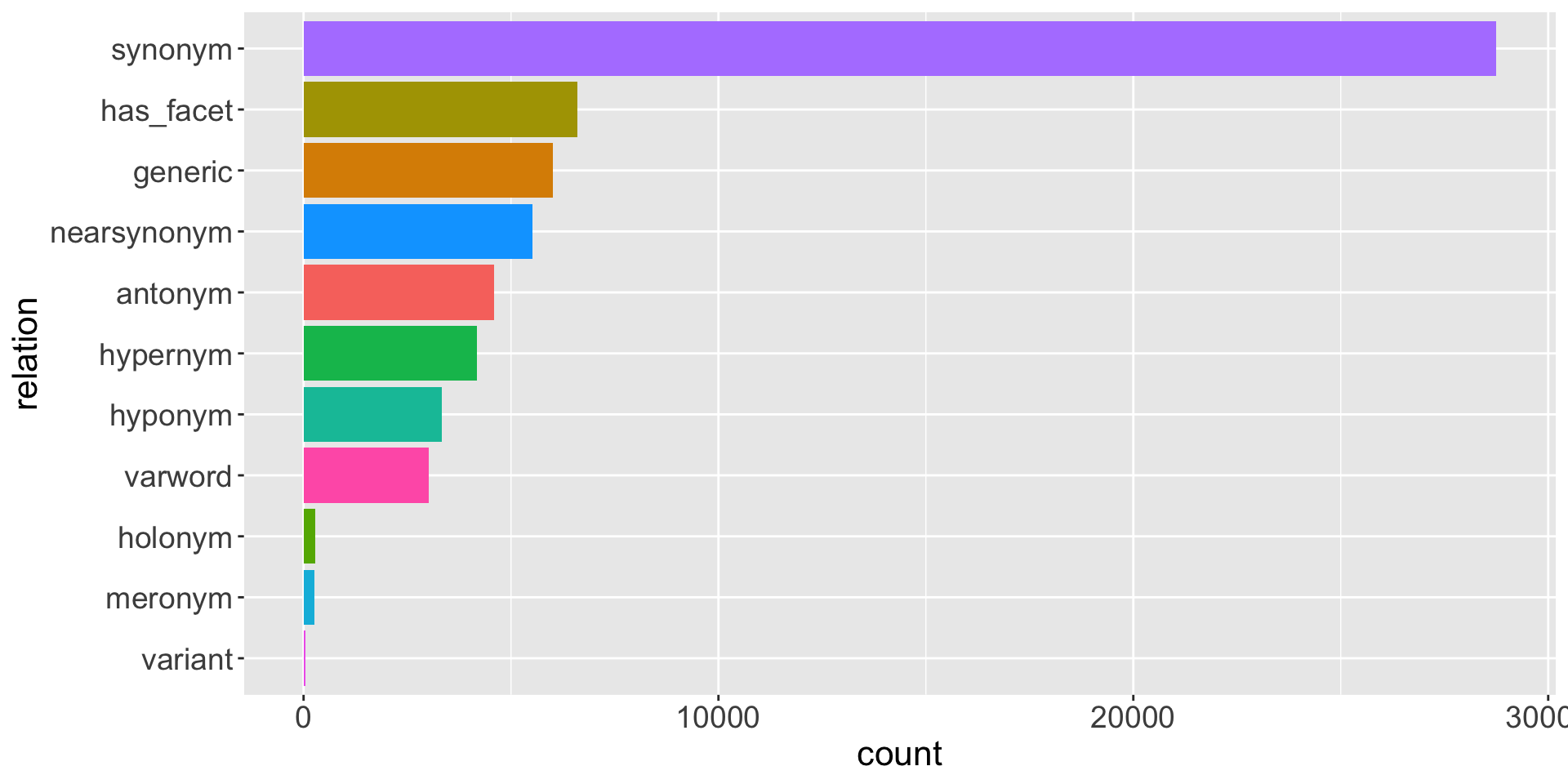
CWN 2.0
Visualization

CWN 2.0
sense tagger
Transformer-based sense tagger
Leveraging wordnet glosses using
GlossBert(huang2019glossbert?), a BERT model for word sense disambiguation with gloss knowledge.Our extended
GlossBertmodel on CWN gloss+ SemCor reports 82% accuracy.
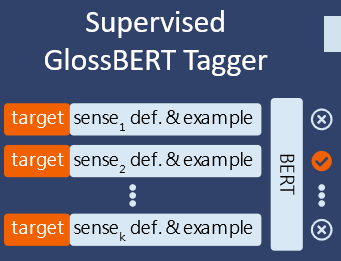
Word Sense Tagger
- APIs (GlossBert version) released in 2021

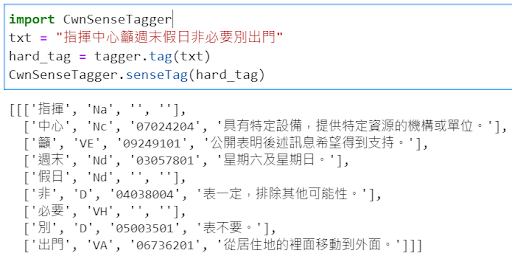
CWN 2.0
Chinese SemCor
- semi-automatically curated sense-tagged corpus based on Academic Sinica Balanced Corpus (ASBC) s.
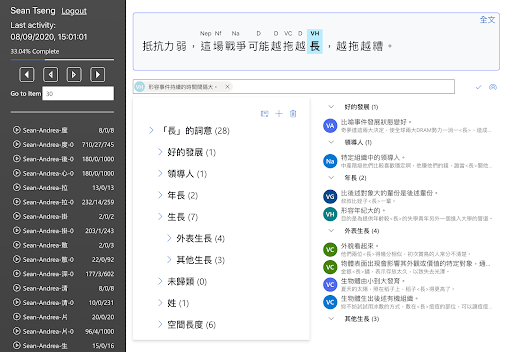
CWN-based applications
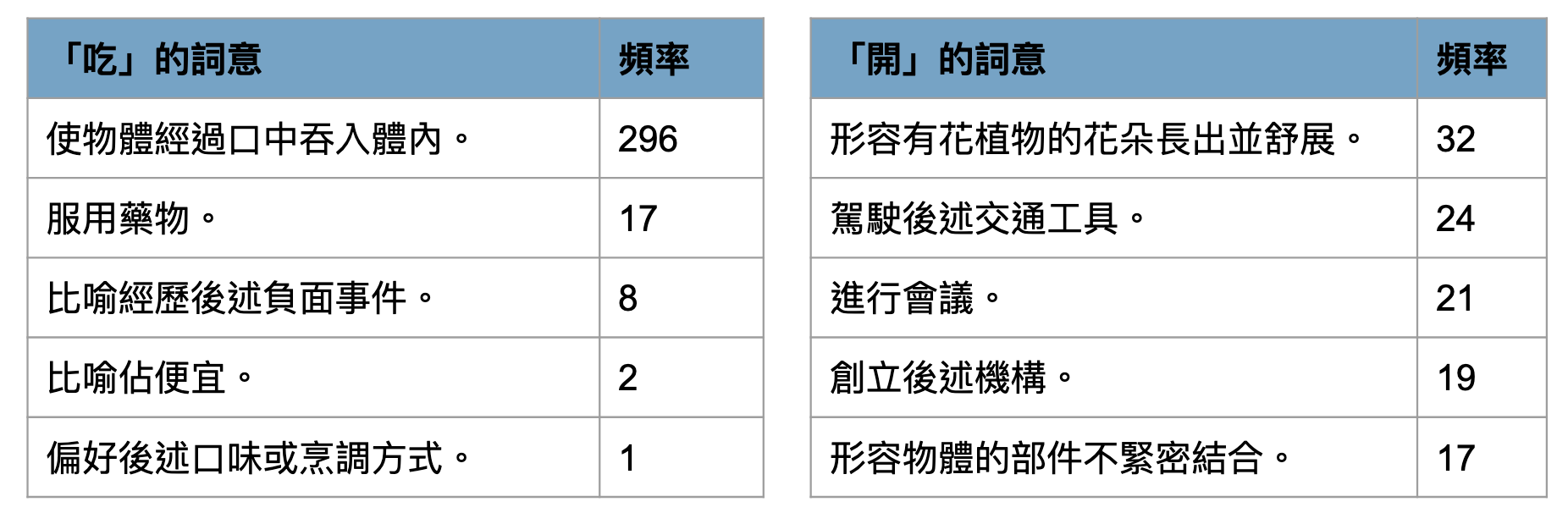
sense frequency distribution in corpus
- Now we have chance to empirically explore the dominance of word senses in language use, which is essential for both lexical semantic and psycholinguistic studies.
- e.g., ‘開’ (kai1,‘open’) has (surprisingly) more dominant blossom sense over others (based on randomly chosen 300 sentences in ASBC corpus)
CWN-based applications
word sense acquisition
credit:郭懷元同學
CWN-based applications
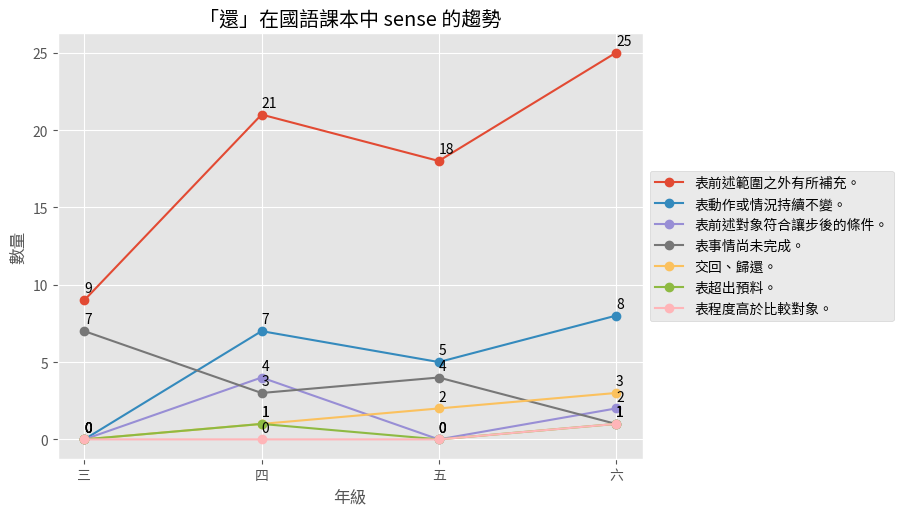
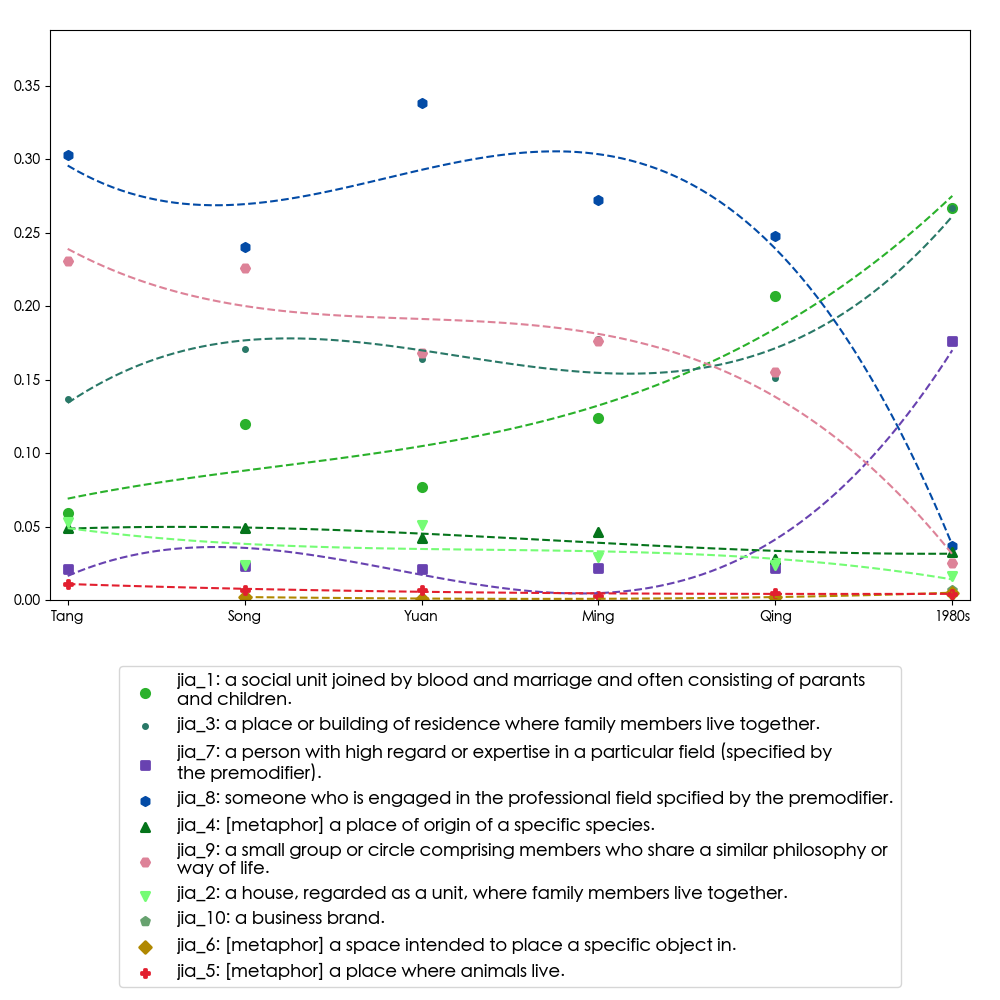
tracking sense evolution
- The indeterminate nature of Chinese affixoids
- Sense status of 家 jiā from the Tang dynasty to the 1980s
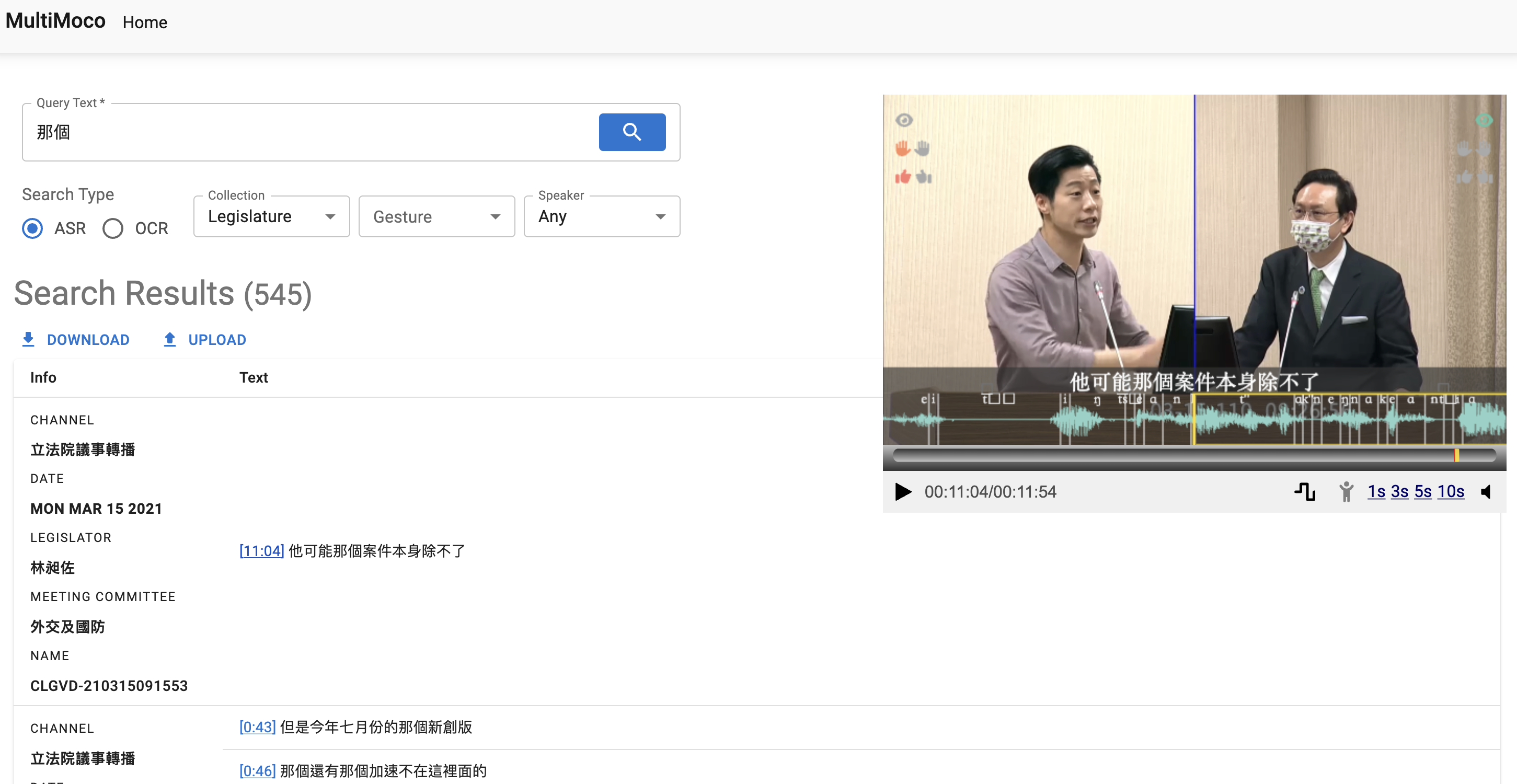
台灣多模態語料庫
LLM-based NLP: a new paradigm
Pre-train, Prompt, and Predict (Liu et al. 2021)
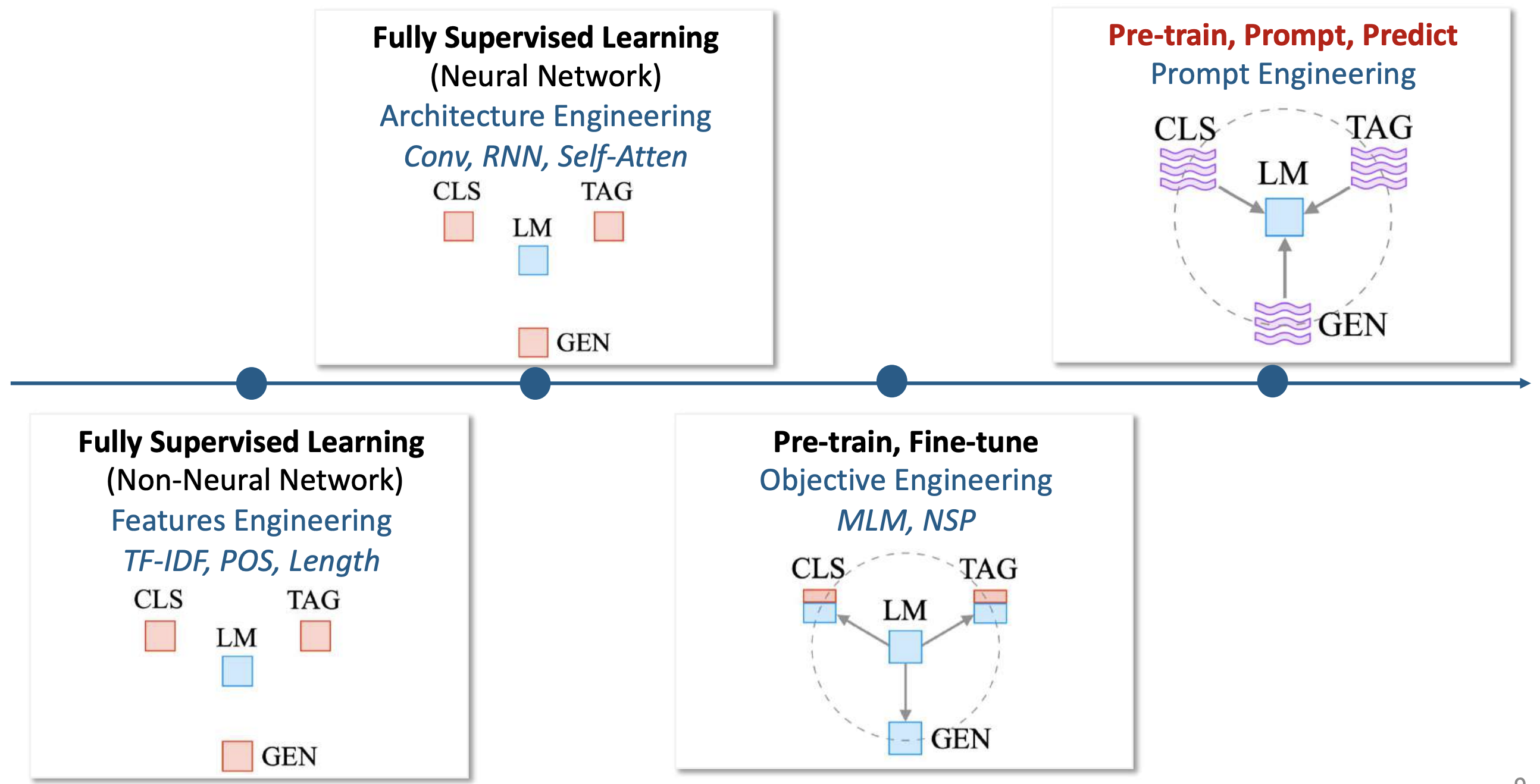
Four paradims in NLP
Prompt and Prompt engineering
Note
prompt: a natural language description of the task.
prompt design: involves instructions and context passed to the LLM to achieve a desired task.
prompt engineering: the practice of developing optimal (clear, concise, informative) prompts to efficiently use LLMs for a variety of applications.

(Text) Generation is a meta capability of Large Language Models & Prompt Engineering is the key to unlocking it.
Prompt and Prompt engineering
basic elements
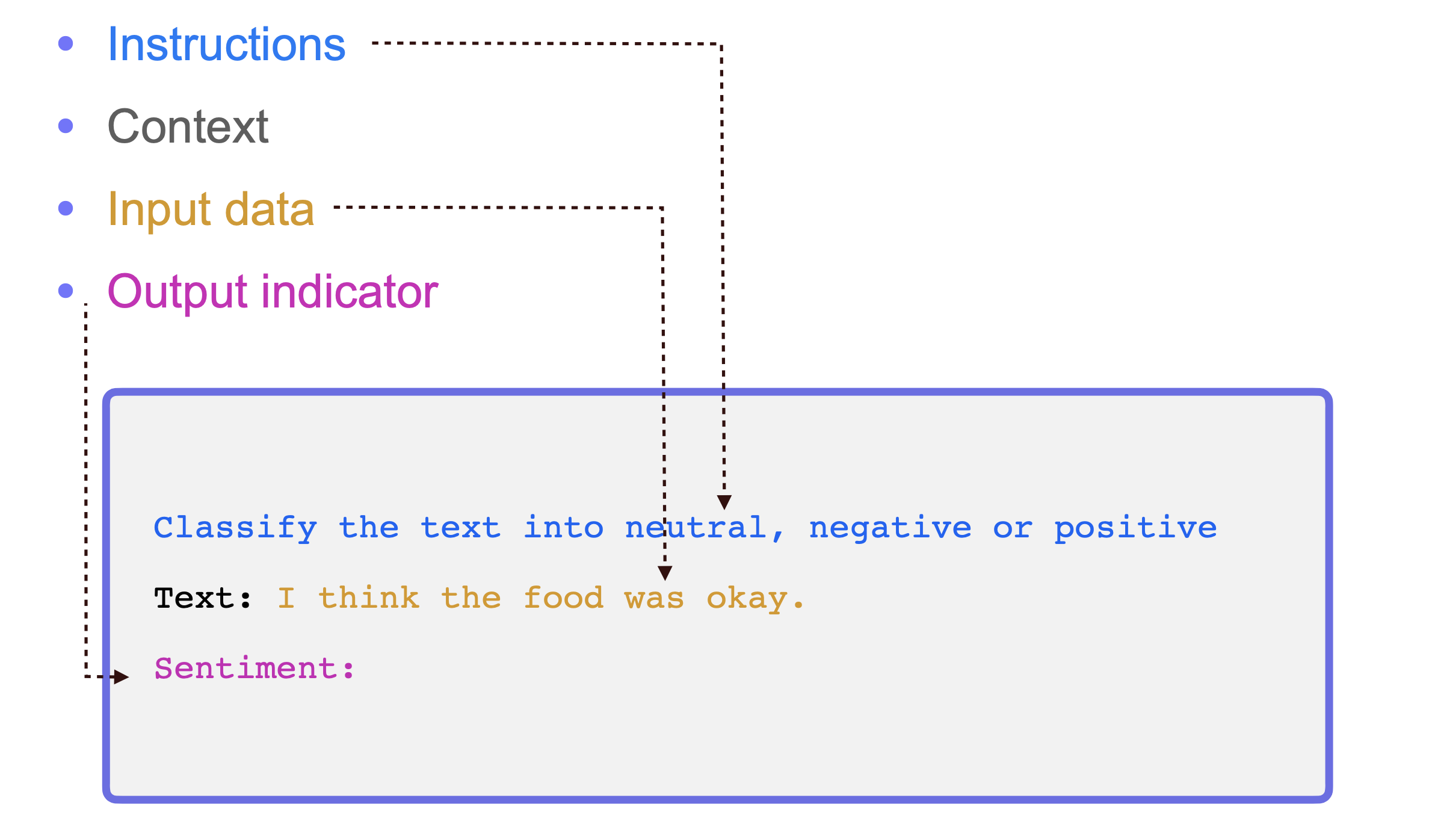
Prompt and Prompt engineering
Chain-of-Thought (Wei et al. 2023)
- generates a sequence of short sentences to describe reasoning logic step by step, known as reasoning chains or rationales, to eventually lead to the final answer.

- zero or few shot CoT
Prompt and Prompt engineering
Persona setting is also important, socio-linguistically
Prompting LLM for lexical semantic tasks
word sense disambiguation

Prompting LLM for solve lexical semantic tasks
sense to action

Prompting LLM for solve lexical semantic tasks
word sense induction

Prompting LLM for solve lexical semantic tasks
code-switching wsd



Results
instruction tuning

Human ratings
Human rating is based on the word’s appropriateness of interpretation, the meanings’ correspondence to the word’s part of speech, their avoidance of oversimplification/overgeneralization, and their compliance with the prompt’s requirements.
The top 600 frequent words are rated to further analyze their error types.
- 數據也有可能受到版權、個資與企業隱私問題。
A neural-symbolic approach to rebuild the LR ecosystem
Toward a more linguistic knowledge-aware LLMs
- The neural-symbolic approach seeks to integrate these two paradigms to leverage the strengths of both: the learning and generalization capabilities of neural networks and the interpretability and reasoning capabilities of symbolic systems.
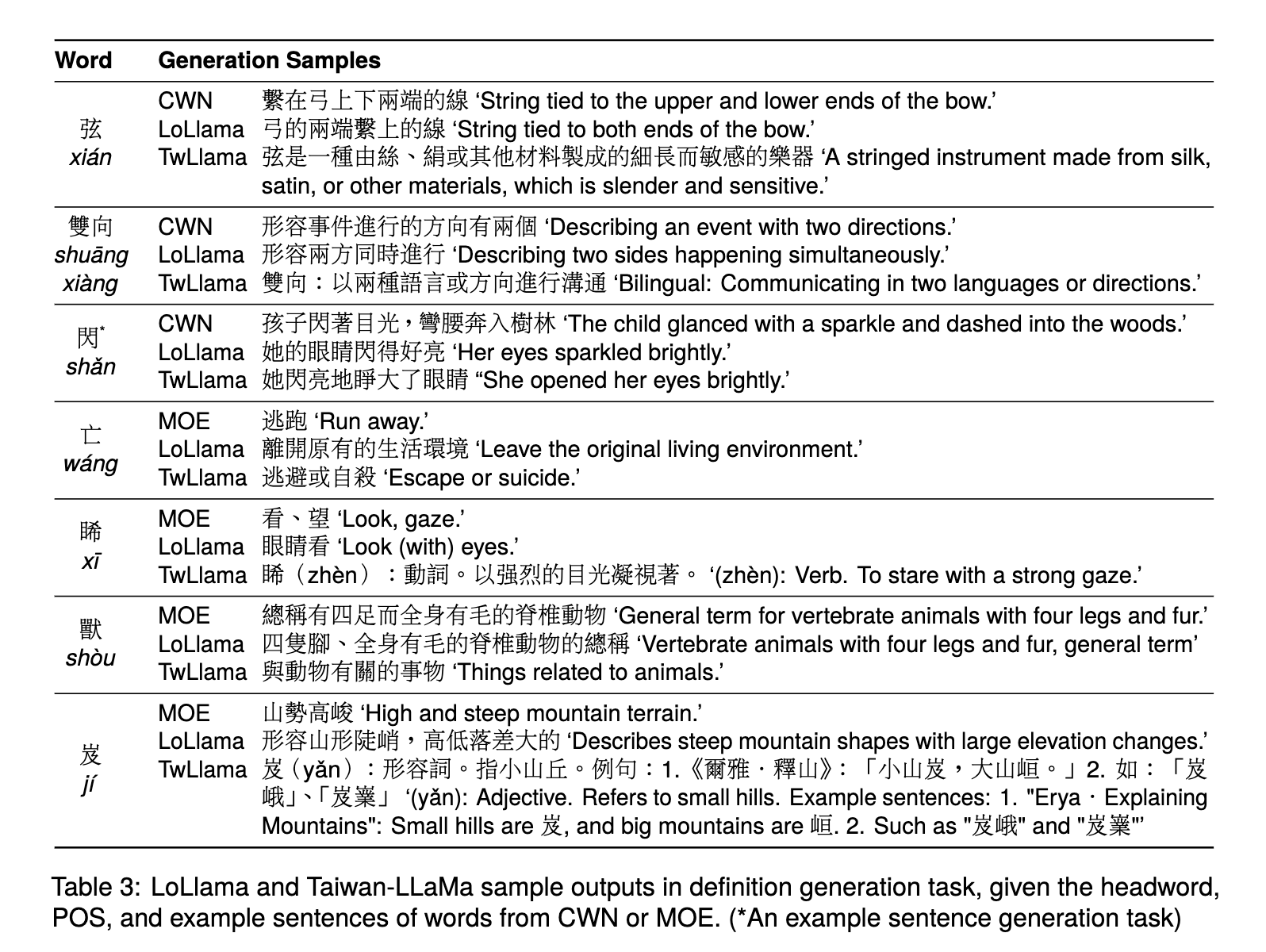
Evaluation
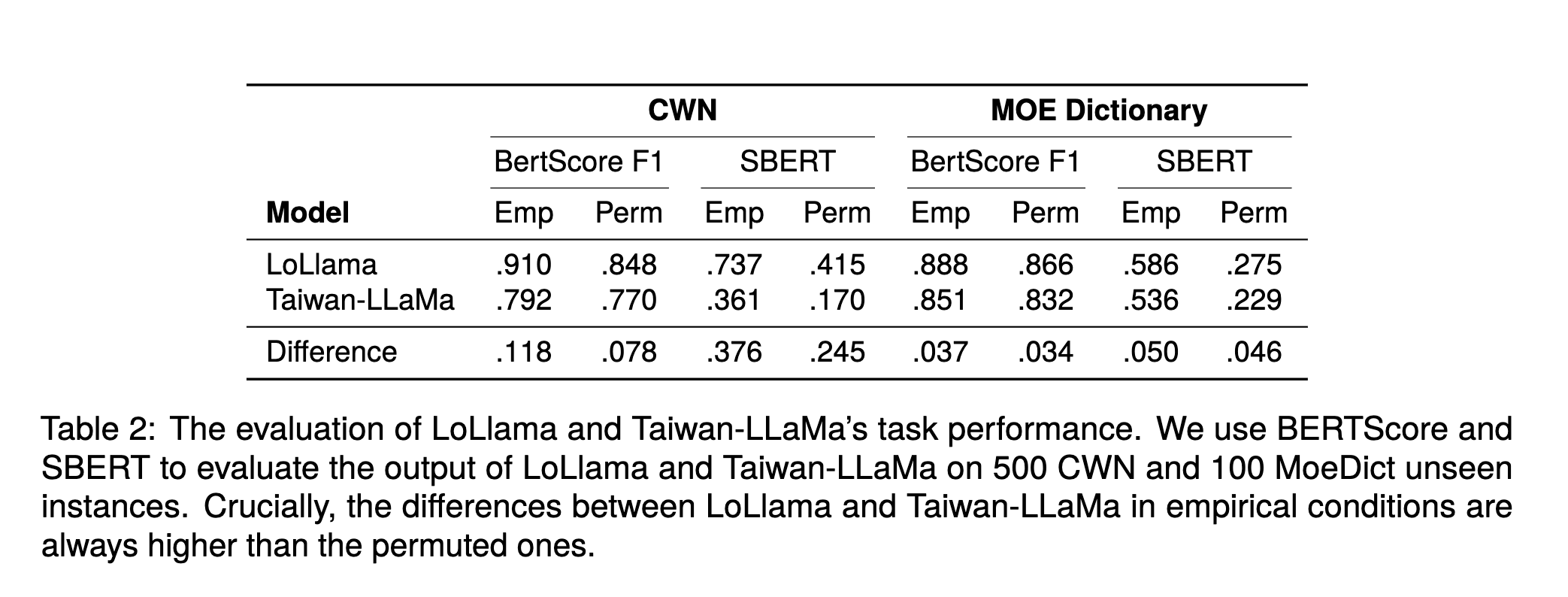
Evaluation
RAG
Retrieving facts from an external knowledge base to ground large language models (LLMs) on the most accurate, up-to-date information and to give users insight into LLMs’ generative process.
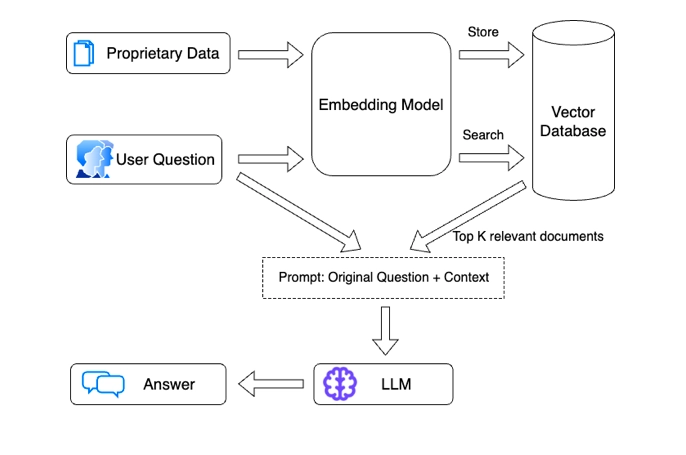
Vector DataBase and Embeddings
- A (vector) embedding is the internal representation of input data in a deep learning model, also known as embedding models or a deep neural network.
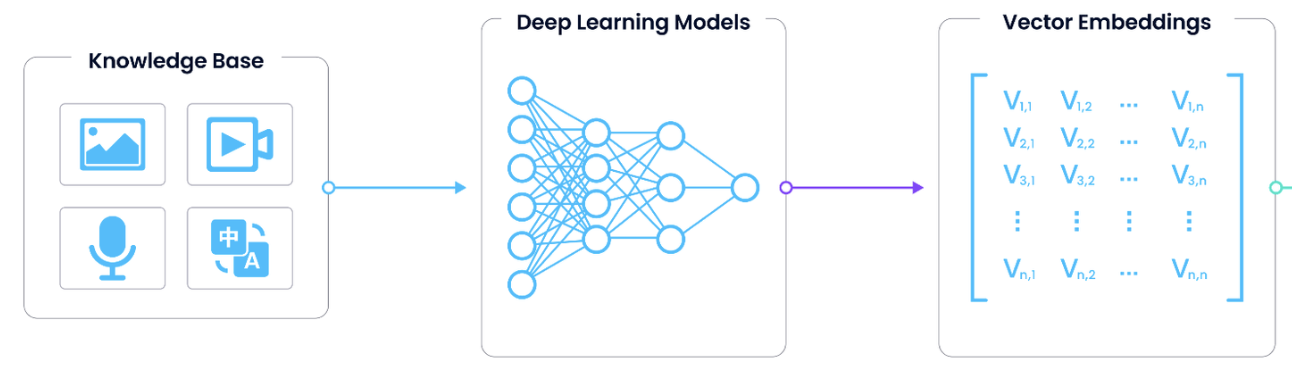
We obtain vectors by removing the last layer and taking the output from the second-to-last layer.
Vector DB/ Vector Stores
Workflow
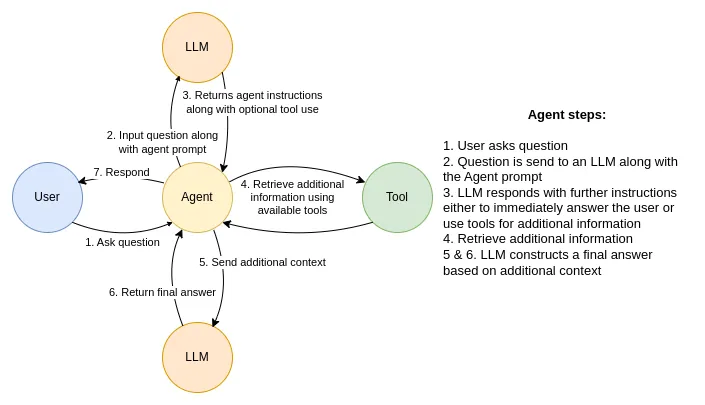
lopeGPT: a RAG model
a higer archtecture 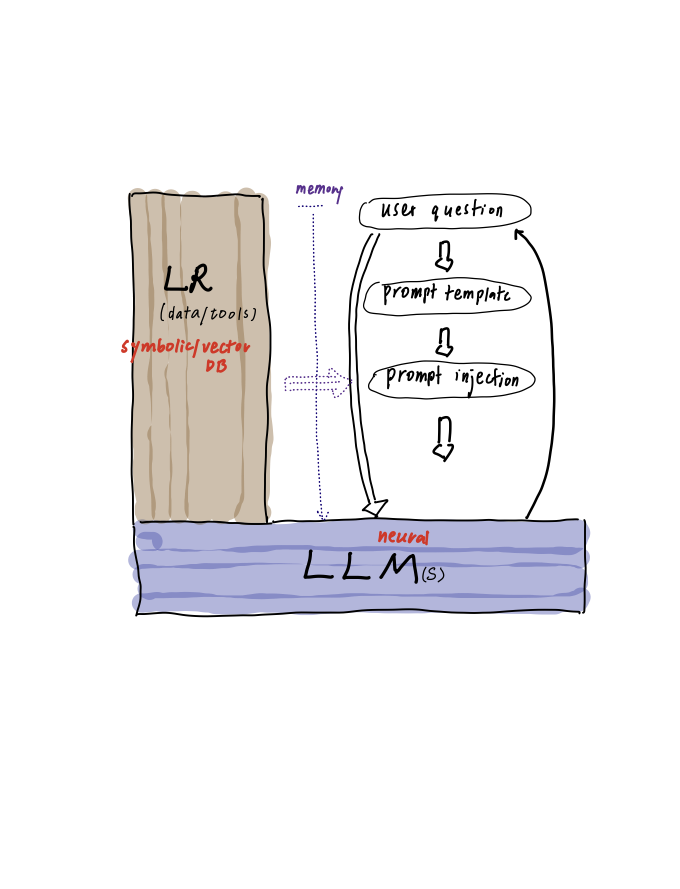
- Integration of language resources:
- Academia Sinica Balanced Corpus of Modern Chinese (ASBC)
- Social Media Corpus in Taiwan (SoMe)
- Chinese Wordnet 2.0 (CWN)



Some prelimenary results
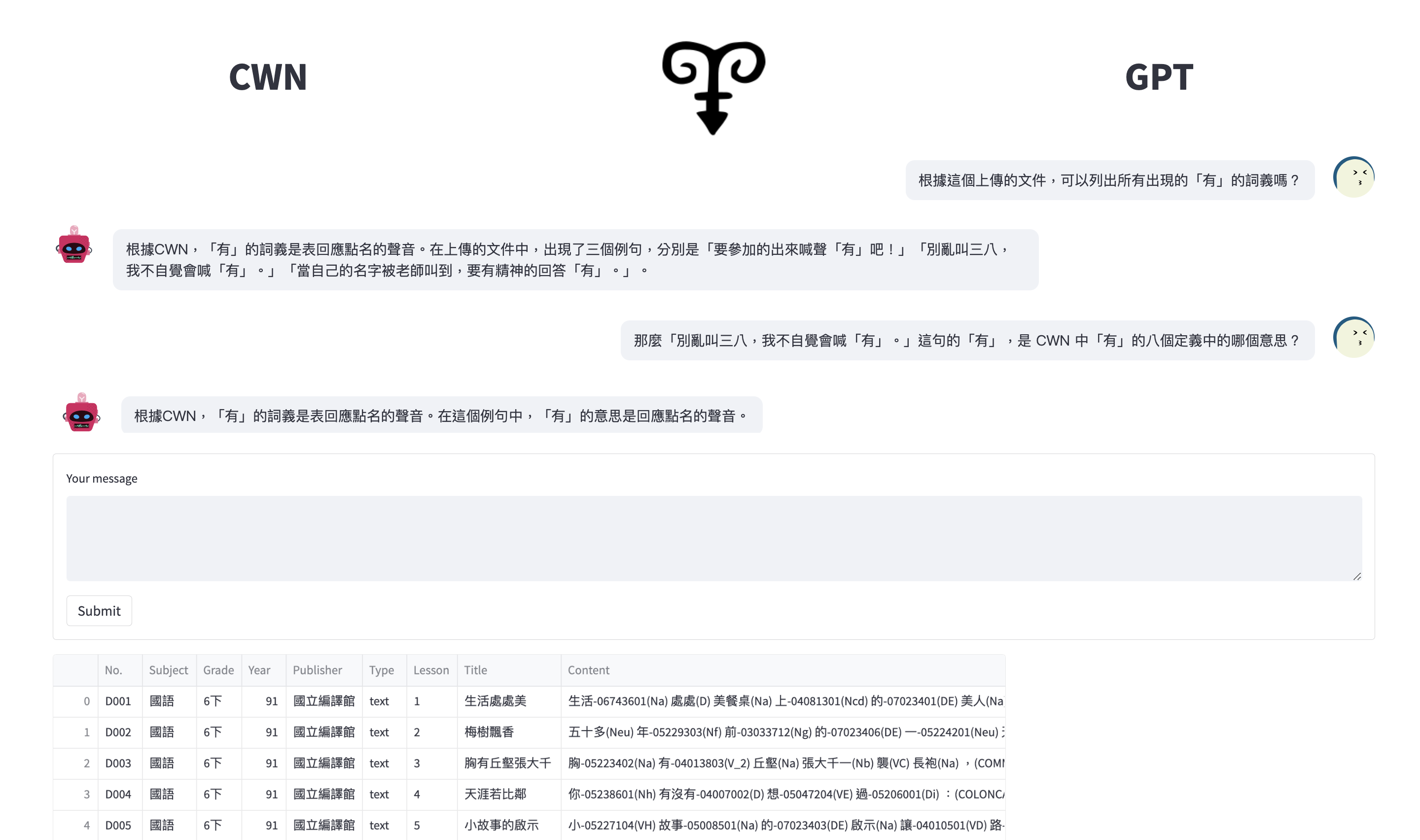
Comparison
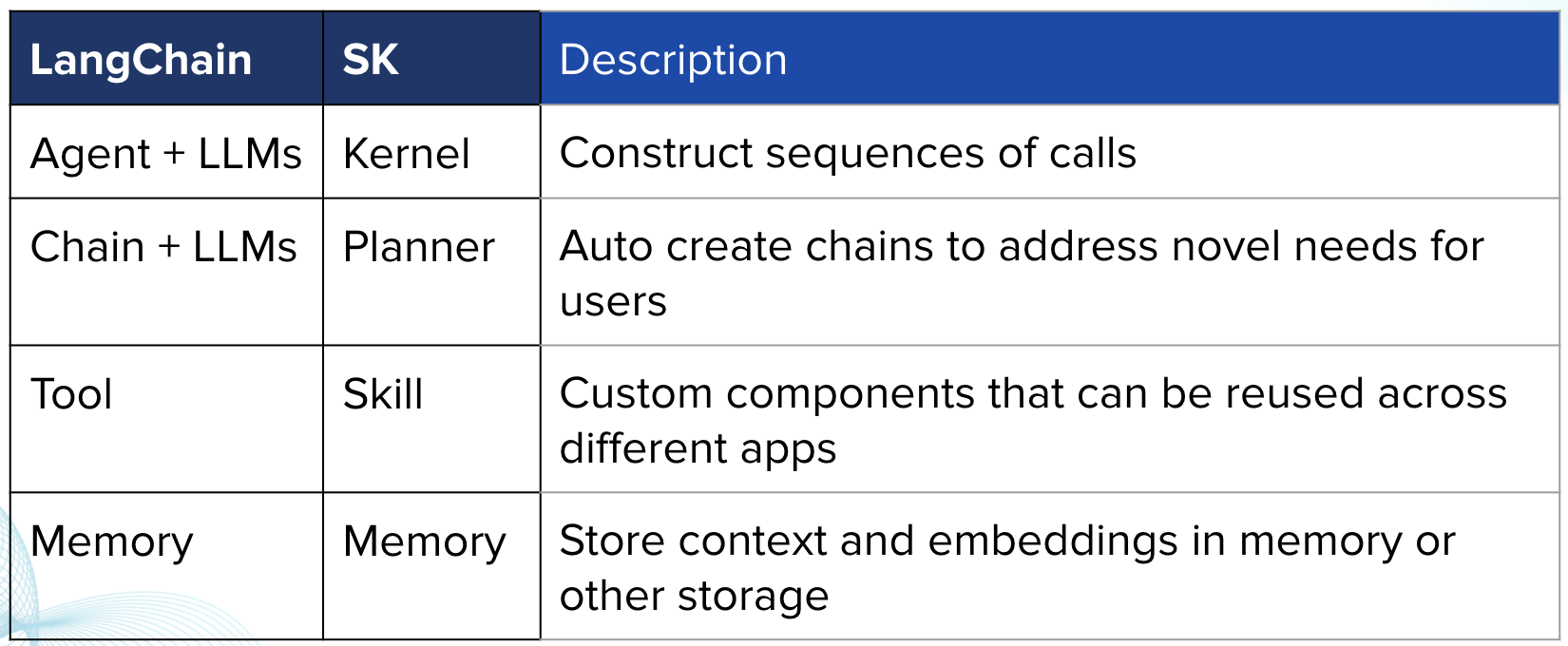
Langchain
langchainis an open source framework that allows AI developers to combine LLMs like GPT-4 with external sources of computation and data.
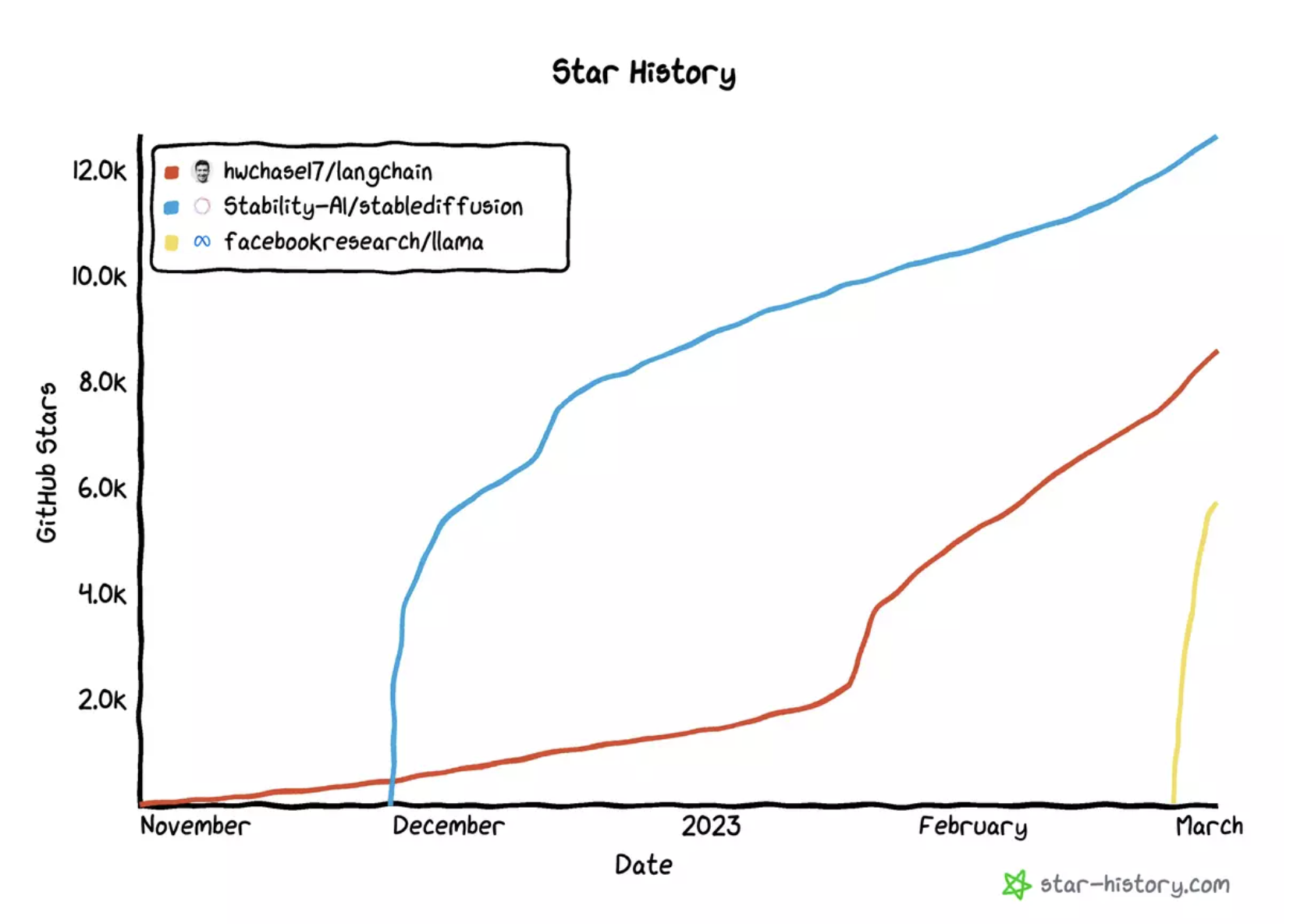
Github repo star history
Architecture
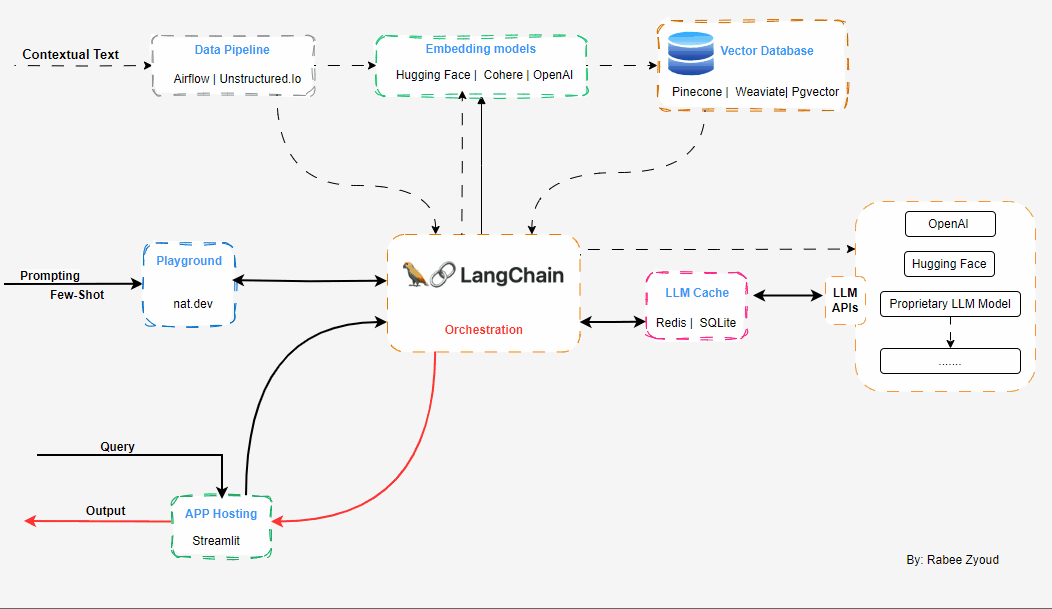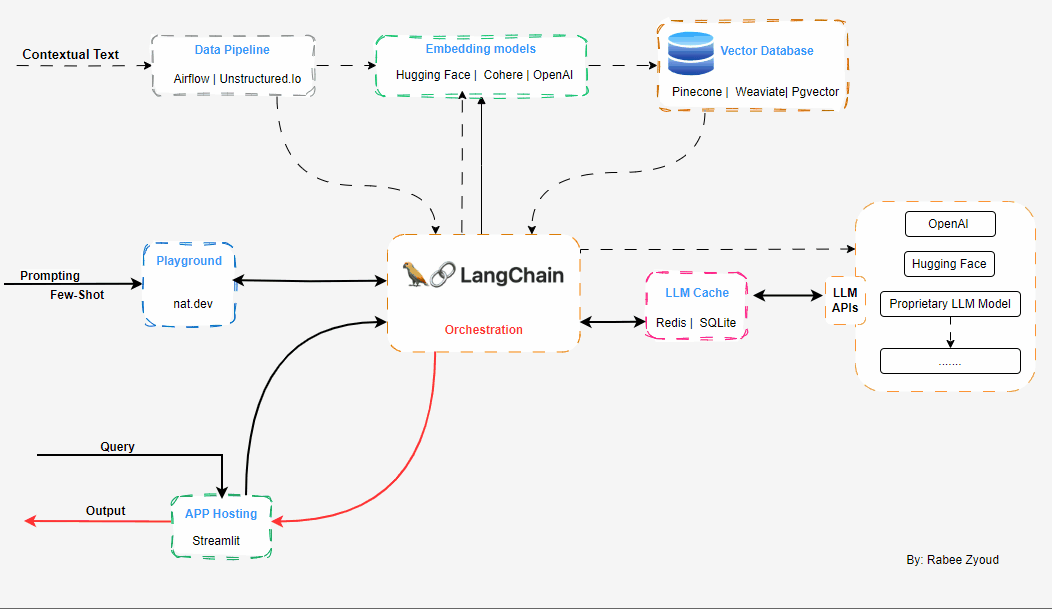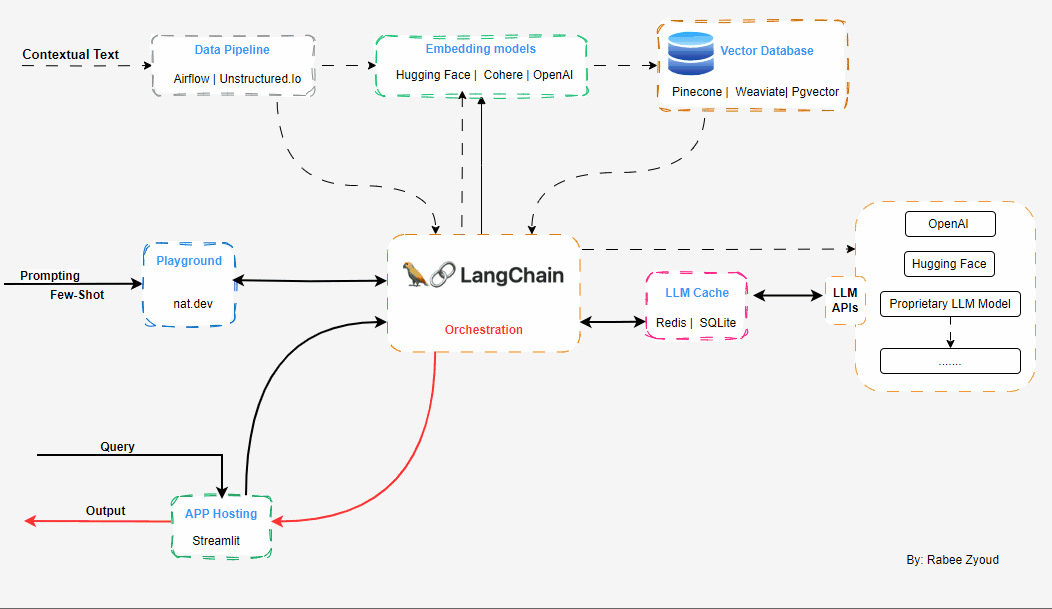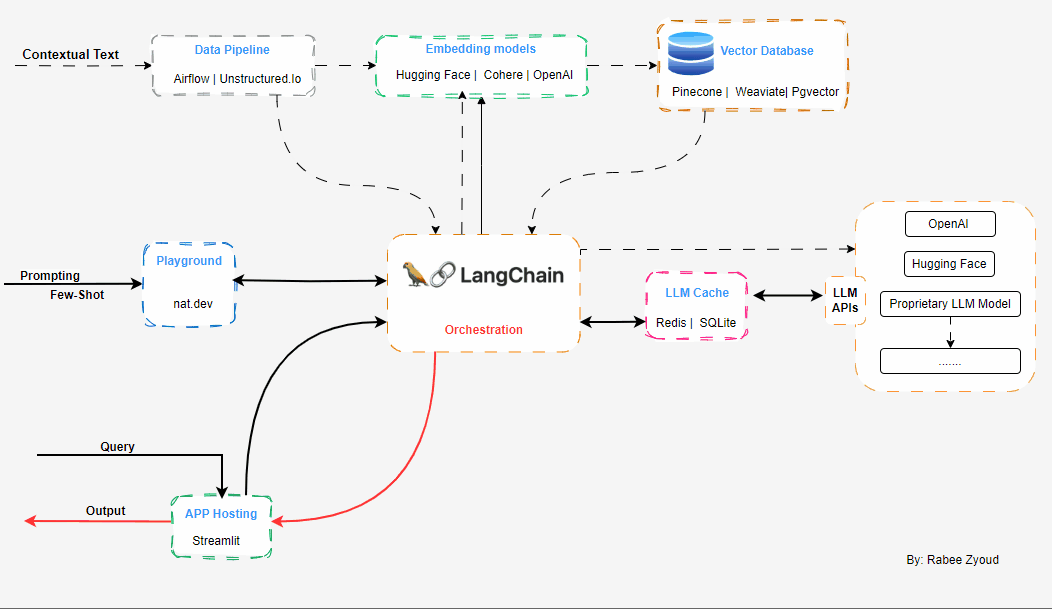
Working with LLMs and your own data
- Good news for Language and Knowledge Resource developers
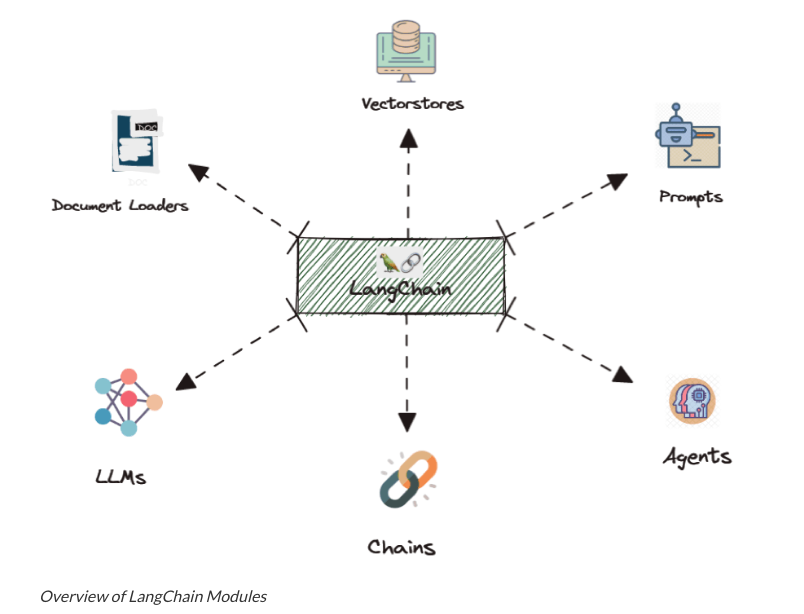
Hands-on coding tutorial



![]()