Chinese Wordnet 2.0
Toward a dynamic interface of lexical synchrony and diachrony
2022-11-02
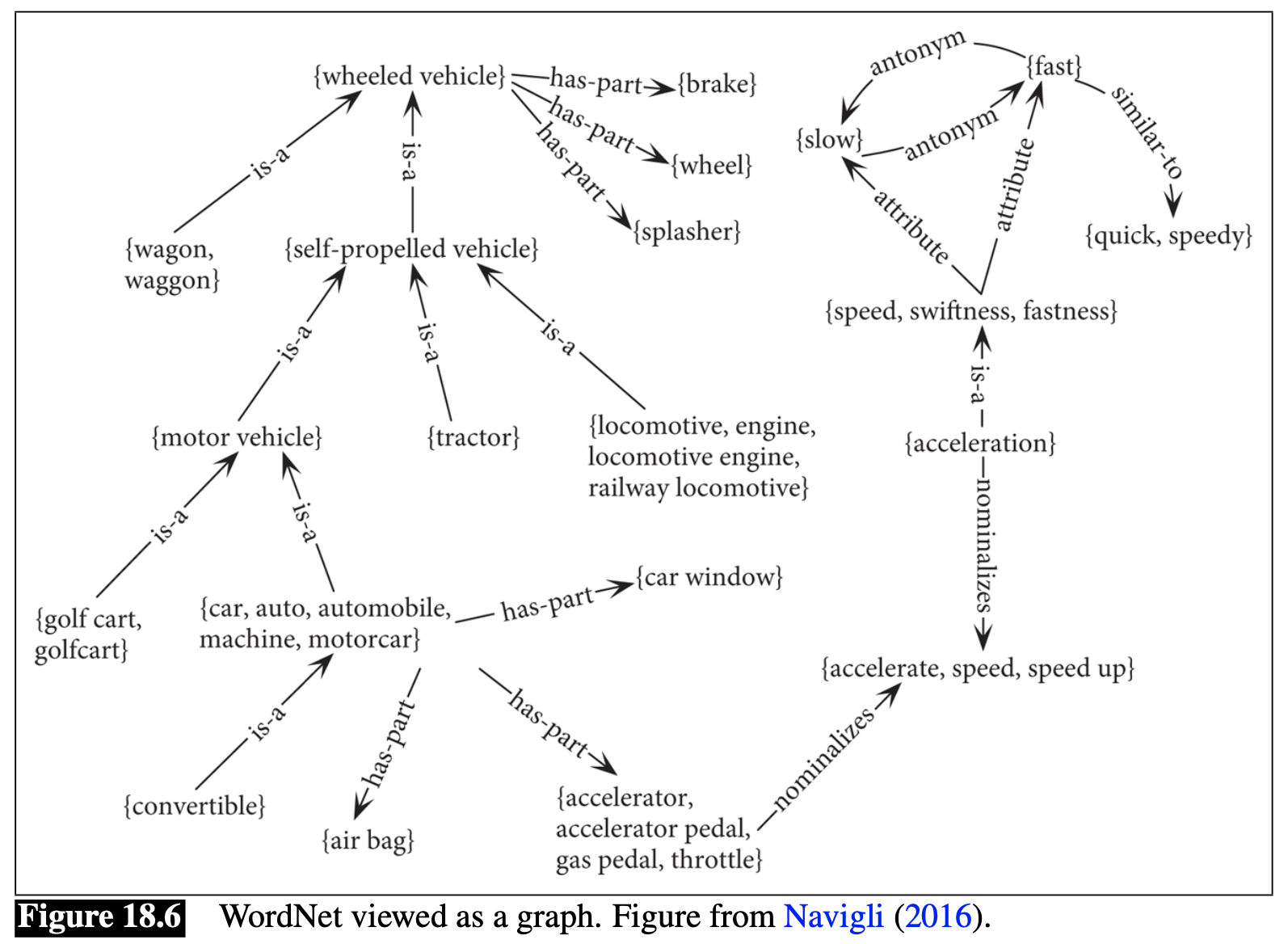
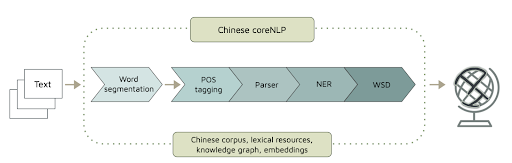
WordNet architecture
Two core components:
- Synset (synonymous set)
- Paradigmatic lexical (semantic) relations: hyponymy/hypernymy; meronymy/holonymy, etc
The status quo
- latest release 2022
- website online
CWN 2.0 Programmable Search
- The most comprehensive and fine-grained sense repository and network in Chinese
- API and doc freely available
Meaning facets vs senses

埔里種的【茶】很好喝
Co-predicative Nouns
a phenomenon where two or more predicates seem to require that their argument denotes different things.
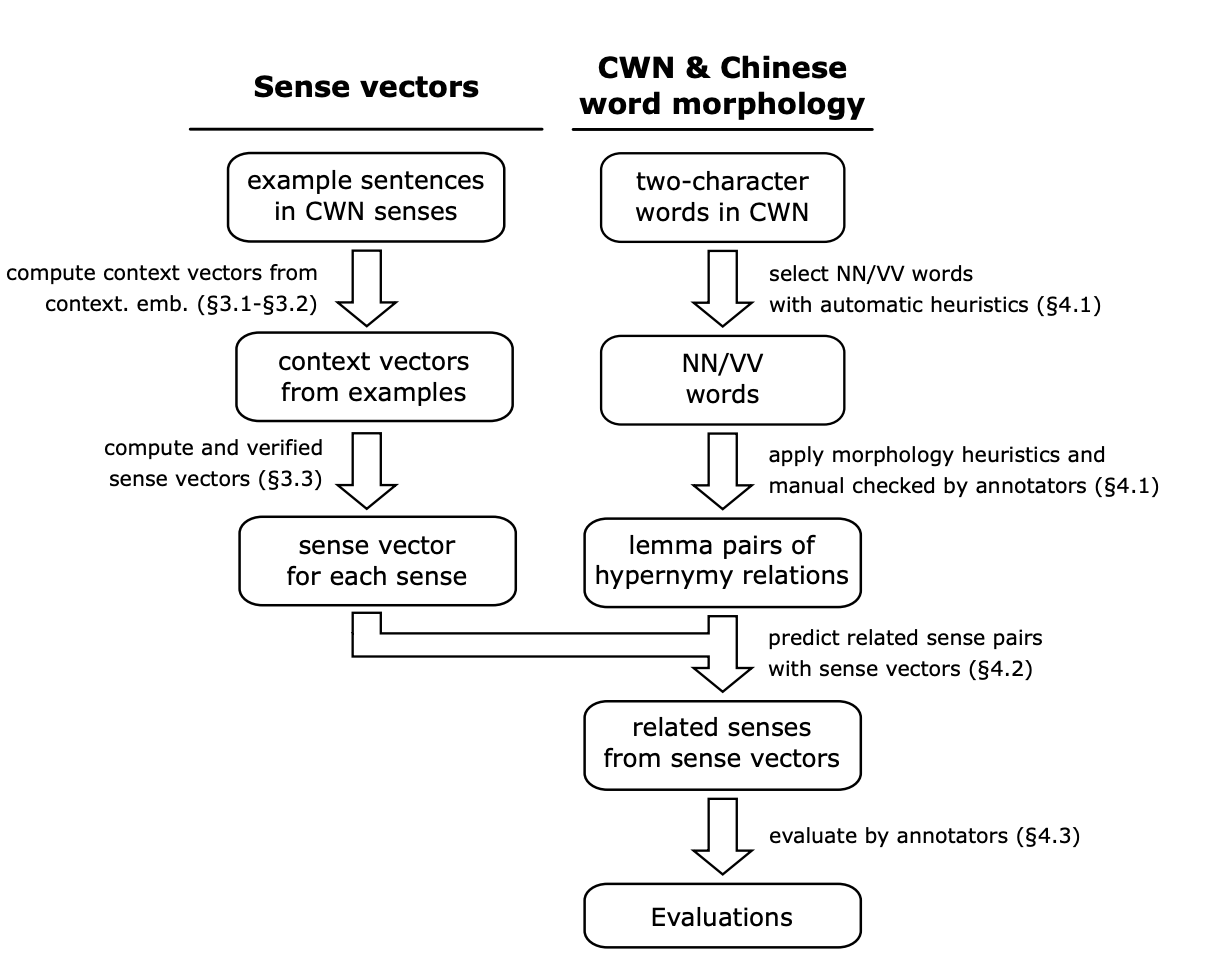
Leveraging morpho-semantic relations

Zipf’s law (no surprise)
- Most words have small number of senses (Zipf’s law)
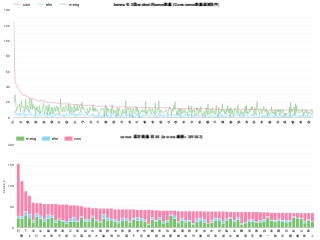
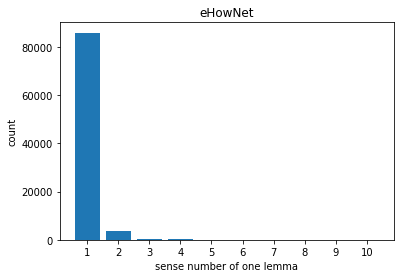
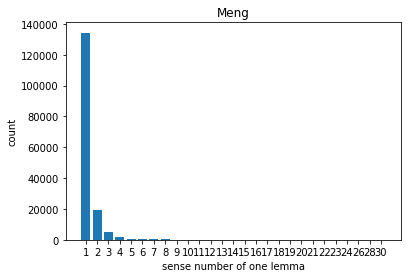
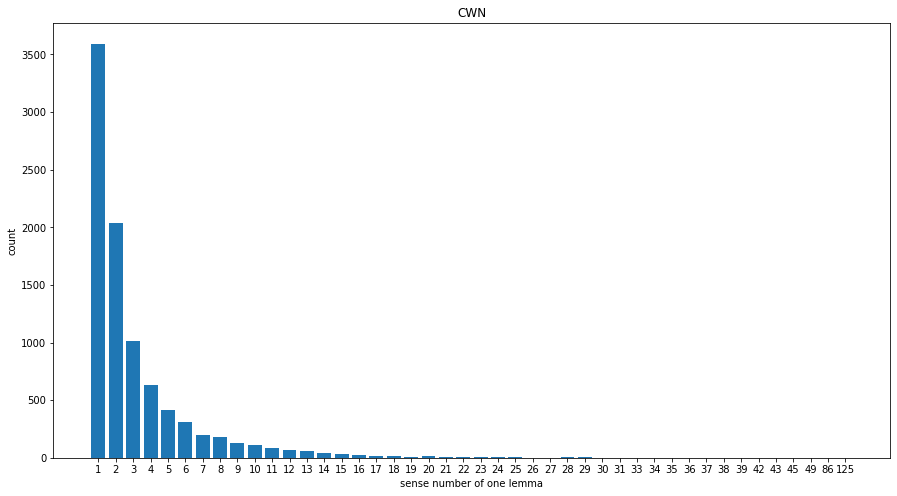
Comparison with others
- CWN is the best candidate
Data summary 1/1
Figure 2 shows the lemma and sense data distribution
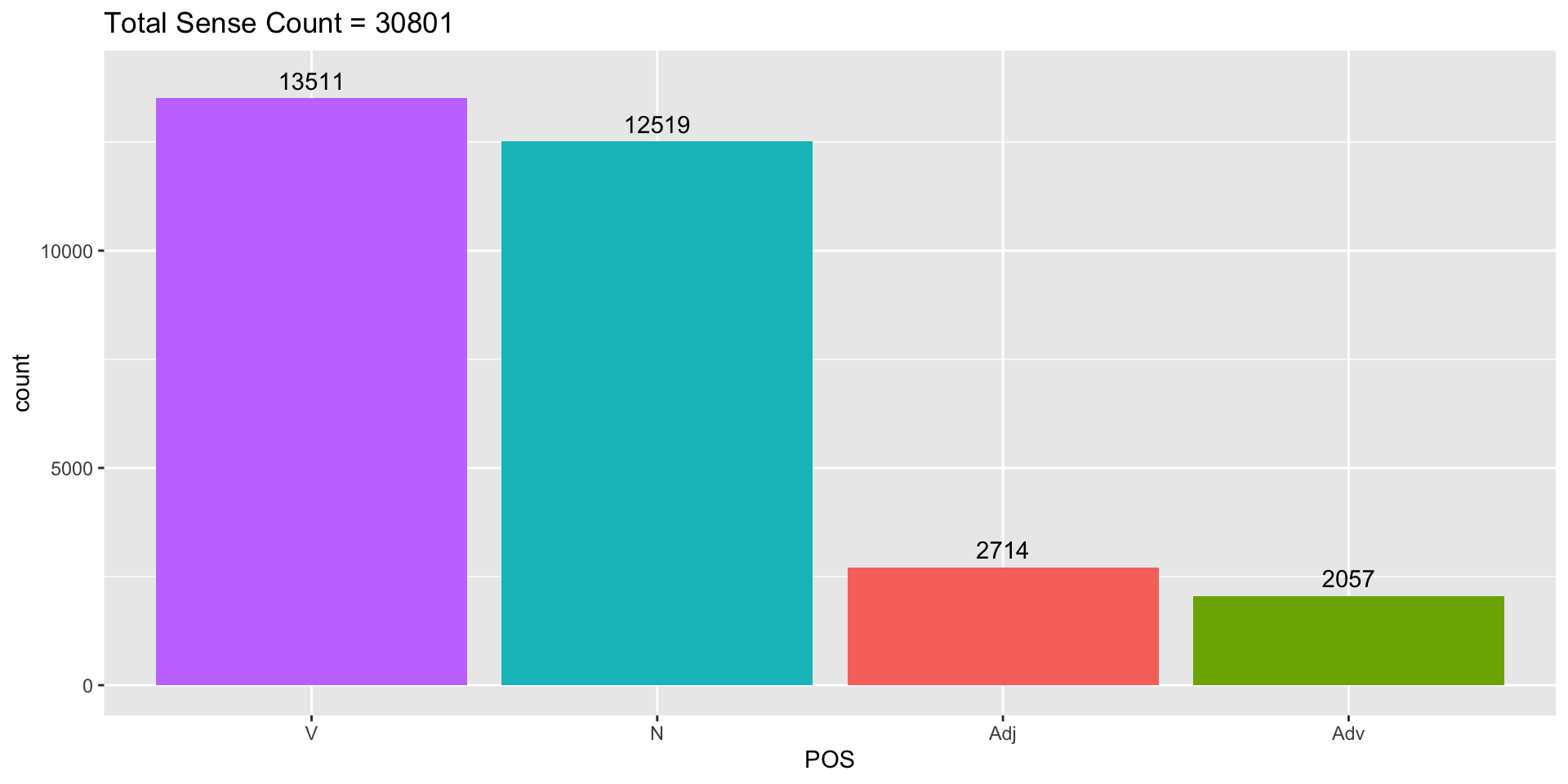
Figure 2: cwn sense data summary
Data summary 2/2
Figure 3 further demonstrates the distribution of different types of relations
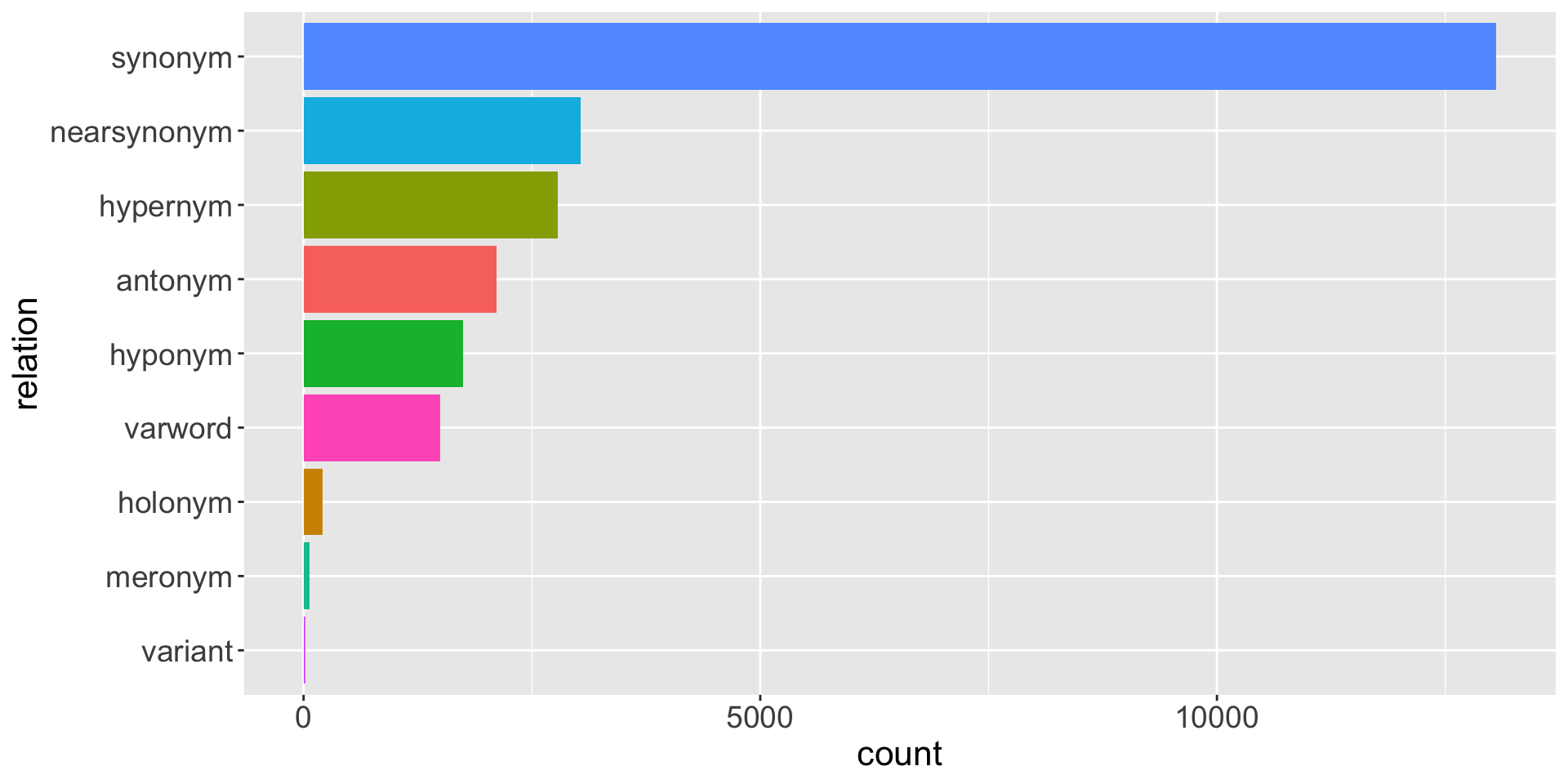
Figure 3: cwn relation data summary
Data summary 3/3
Gloss statistics
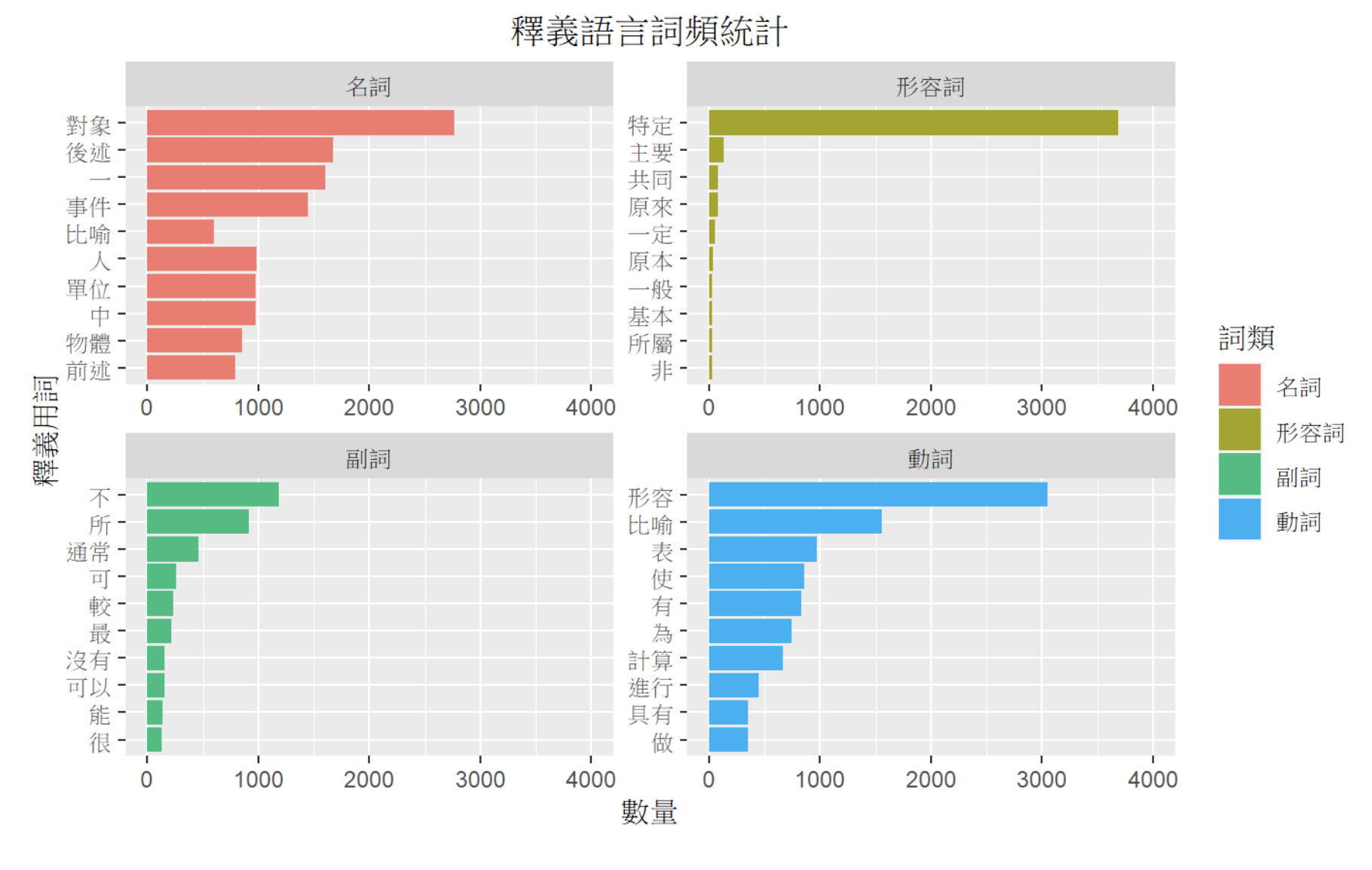
GraphAPI and Visualization

SemCor manually sense-tagged corpus
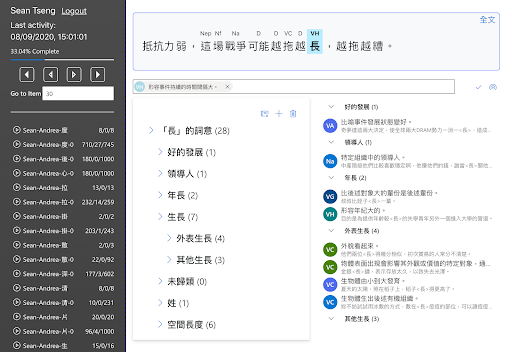

Word Sense Tagger
WSD: The Problems
The task as currently defined does not allow for generalization over different words \(\rightarrow\) learning is word-specific.
Need training data for every sense of every word, and no chance with unknown words. (unsupervised approaches perform consistently worse than supervised approaches)
Cannot capture the sense alternation regularities
![]()
WSD with Transformer (1)
- Leveraging wordnet glosses using
GlossBert(L. Huang et al. 2019)- a BERT model for word sense disambiguation with gloss knowledge.
- Our extended
GlossBertmodel on CWN gloss+SemCor reports 82% accuracy.
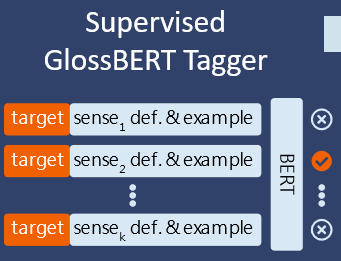
Word Sense Tagger
- APIs (GlossBert version) released in 2021

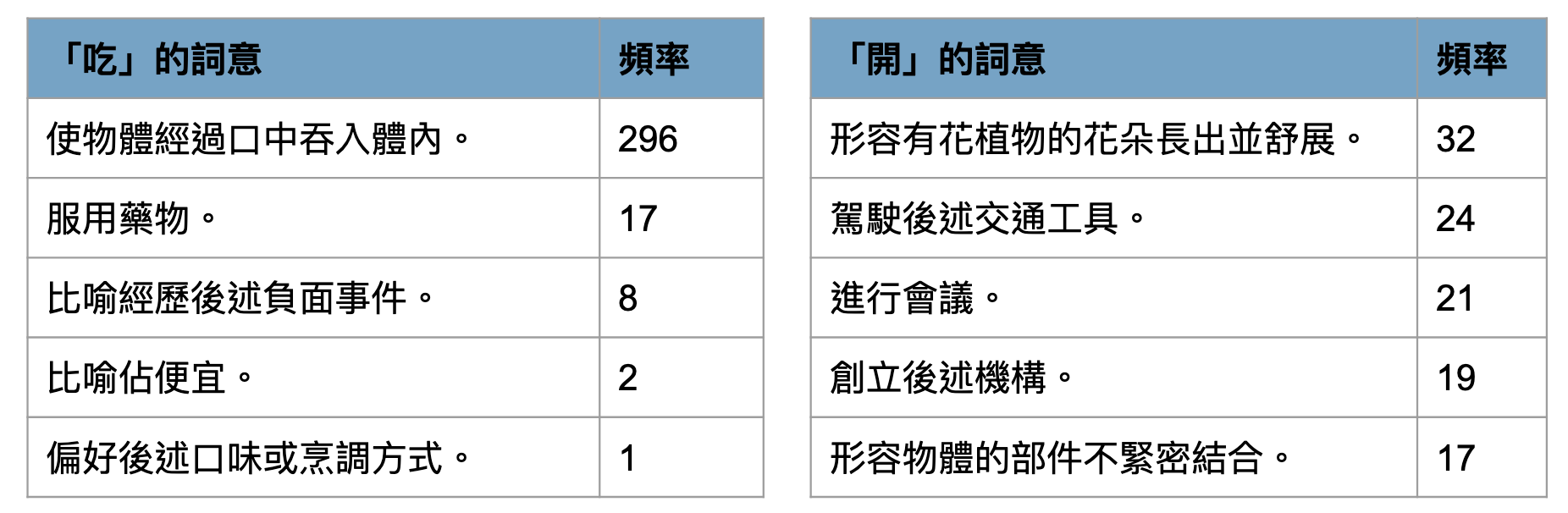
Word Sense frequencies
Now we have chance to empirically explore the dominancy of word senses, which is essential for both lexical semantic and psycholinguistic studies.
- e.g., ‘開’ (kai1,‘open’) has (surprisingly) more dominant blossom sense over others (based on randomly chosen 300 sentences in ASBC corpus)
Other related works
- Resolving Regular Polysemy in Named Entities (Hsieh et al. submitted)

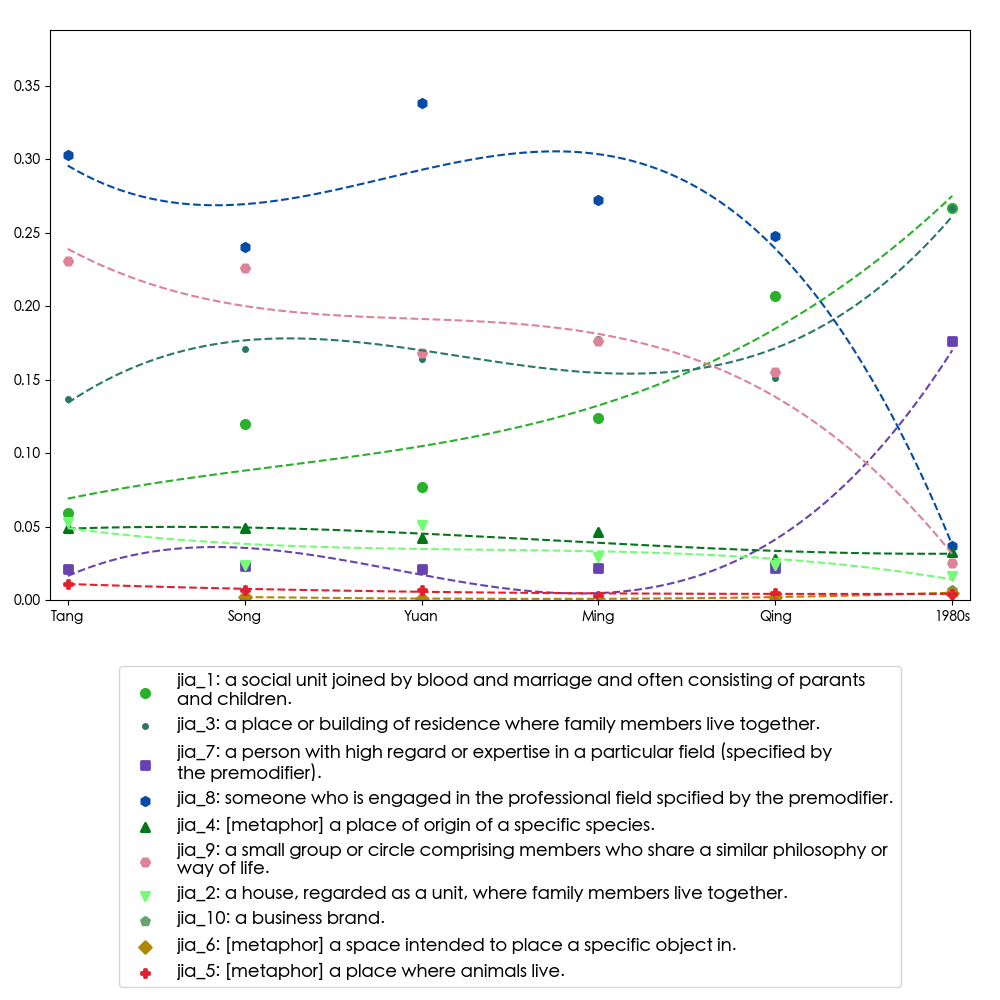
Change of affixiod status in diachrony
- The indeterminate nature of Chinese affixoids
- Sense status of 家 jiā from the Tang dynasty to the 1980s
Dynamics in Contemporary Mandarin Chinese(s)
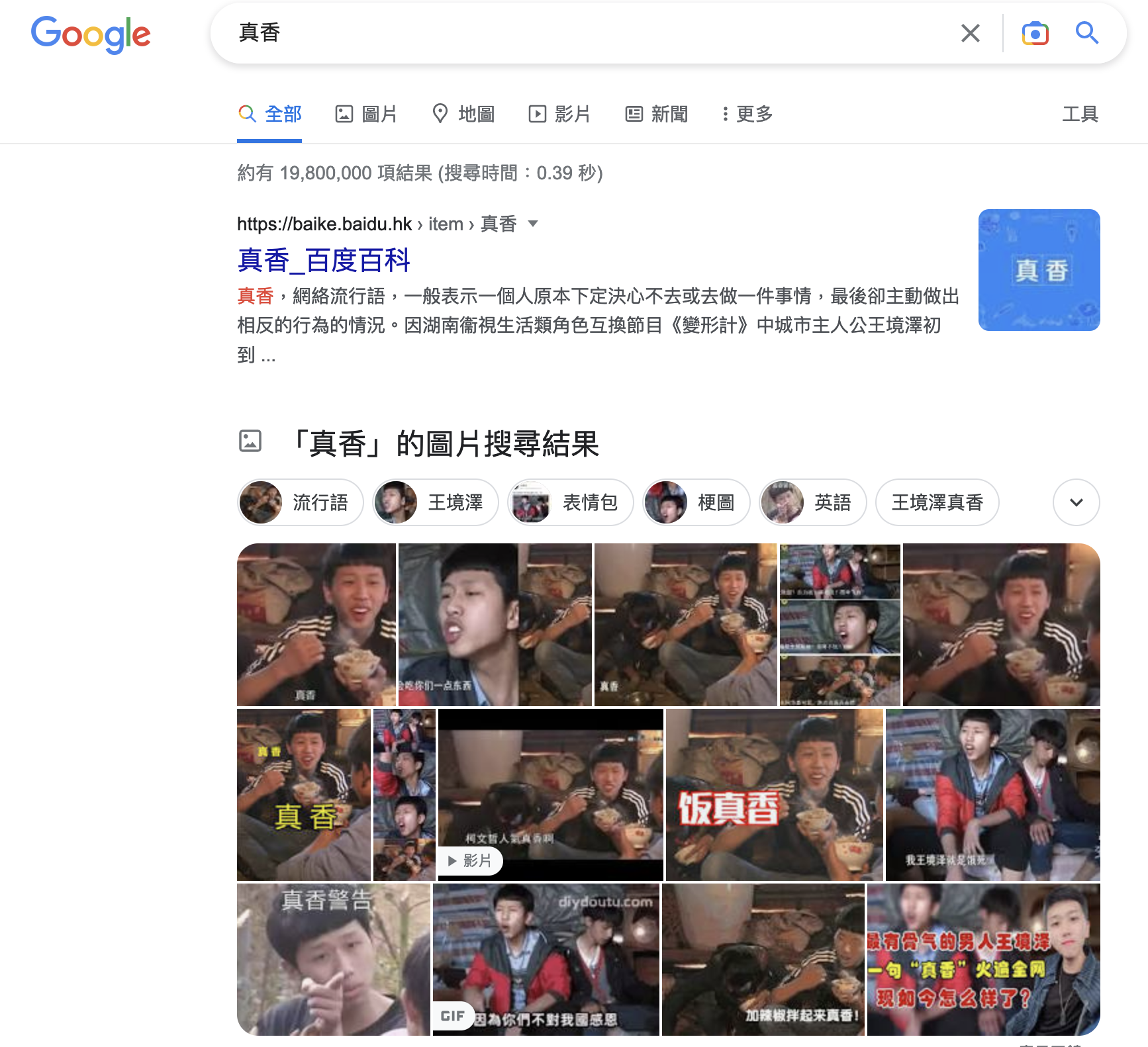
【真香】 (‘zhēn xiāng’, soappetizing)

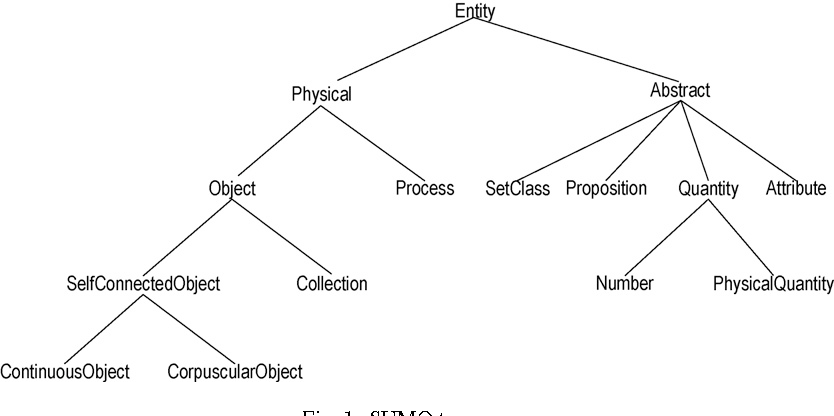
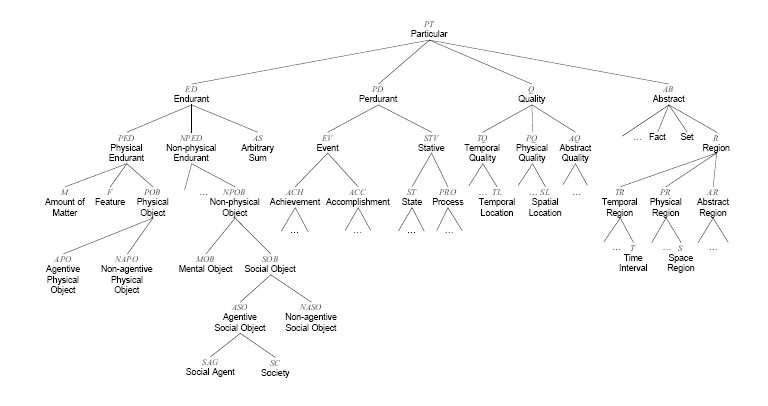
Re-structuring Ontologies
synset-structured (lexicalized) ontology doesn’t (seem) work well
unlabeled root vs embodied body

Reference
