Previous slide Next slide Toggle fullscreen Open presenter view
本週學習內容
Python 基礎
conditions and branching
more on data types
File and OS operations
Data Science Process
Data in Data Science
Simple deployment of a DS web app
再次強調
AI pair-programming is not close, it's here
source
快速複習
上次談了程式環境、變數、運算式、基本資料型別、運算式 (expression) 和陳述式 (statement)。
Quiz
今天續談幾個重要的陳述式 Statement
先從語言學的角度聊聊
A statement is an illocutionary act that has the assertive illocutionary point of saying that some state of affairs is true. A statement is a sentence having a form that is typically used to express such illocutionary acts (such as an English declarative sentence which has a subject followed by a verb).
語言學對於句式的一種分類
Statement 陳述句Question 問句
Commands (Imperatives) 命令句
Exclamations: 感嘆句
自然語言與程式語言的神奇接合
Assignment Statements
這是當你想給某個變數賦值時使用的陳述。
a = "shukai"
Conditional Statements
允許我們根據某些條件執行特定代碼與任務。例如,if, elif, 和 else:
x = 15
if x > 10 :
print ("x is greater than 10" )
elif x == 10 :
print ("x is 10" )
else :
print ("x is less than 10" )
剛好來複習一下,前面六行的程式碼,哪些是 expression (傳回了什麼),哪些是 statement (做了什麼)?
Loop Statements
當重複執行某段代碼時,你會使用迴圈。例如,for 和 while:
for i in range (5 ):
print (i)
j = 0
while j < 5 :
print (j)
j += 1
Function Statements
既然先碰到了 range(),順便簡介一下函數的概念。
當你想要封裝某些功能或代碼片段時,你可以使用函數陳述式。
可以想像函數是一個小型的、獨立的程式片段:你給它設好一些輸入(參數 parameter),呼叫它時,它能處理呼喚者的輸入(引數 argument),然後輸出(或稱返回值)。
def greet (name ):
print ("妳好, " + name + "!" )
greet("Shukai" )
range()
Python 內建的函數,常用於創建數字序列,非常適合用在 for 迴圈陳述式中。
使用一個參數 range(stop),會產生一個從 0 到 stop-1 的整數序列。
使用兩個參數 range(start, stop),會產生一個從 start 到 stop-1 的整數序列。
使用三個參數 range(start, stop, step),會產生一個從 start 到 stop-1 的整數序列,每個數字之間的間隔為 step。
也學習一種炫技法 list comprehension
一種簡潔快速生成列表的方法。它用一行表達式就能生成一個新的列表,通常這個表達式會包含一個迴圈和一個條件語句。
example_1 = [i for i in range (5 )]
example_2 = [i for i in range (2 , 5 )]
example_3 = [i for i in range (2 , 10 , 2 )]
example_1, example_2, example_3
課堂練習
假設我們有一群學生的體重數據,我們想要:
計算平均體重
找出所有體重小於60的學生
找出所有體重大於等於90的學生
提示
使用 for 迴圈來遍歷每個學生的體重
使用 if 條件判斷來檢查每個學生的體重是否達到我們的標準
貼在這個協作環境 replit
scores = {
'Alice' : 95 ,
'Bob' : 78 ,
'Charlie' : 82 ,
'David' : 60 ,
'Eva' : 55 ,
'Frank' : 92 ,
'Grace' : 45 ,
'Henry' : 97
}
課堂練習(稍微進階)
假設我們有一個購物清單和一個預算。我們想要:
確保我們購買的每一項物品都在我們的預算範圍內
計算我們購買的所有物品的總價格
確定我們是否超出預算,如果超出,我們需要找出最昂貴和最便宜的物品
shopping_list = {
'Apple' : 0.5 ,
'Banana' : 0.2 ,
'Cherry' : 0.7 ,
'Date' : 1.5 ,
'Fig' : 2.0
}
budget = 5.0
File and OS operations
File I/O(Input/Output)涉及到讀取(Input)和寫入(Output)文件。
OS operations 涉及到操作作業系統中的文件和目錄,例如創建、刪除、重命名等。
今天先學習 File I/O,OS operations 留到以後再說。
開啟、讀取、寫入、關閉
使用 open() 函數來開啟文件,這個函數需要兩個參數:文件名稱路徑和模式(讀取 'r'、寫入'w'、附加'a'等)。
file = open ("example.txt" , "r" )
file.read():
file.readline():
file.readlines():
問題
open() 函數的讀取模式(read mode)和 file.read() 方法之間的區別?
file = open ('example.txt' , 'r' )
content = file.read()
file.write(string):
關閉文件 file.close()file.close() 關閉文件是一個好習慣,以確保所有的變化都被儲存。
推薦使用 with 陳述式
使用 with 可以確保文件在使用後會被正確關閉。
with open ("example.txt" , "r" ) as file:
content = file.read()
在這個例子中,file 會在 with 代碼塊結束時自動關閉
常用的 csv 檔案操作
讀取 CSV(Comma Separated Values)文件是一個常見的任務,有兩種常用方式。
import csv
with open ('weight.csv' , mode='r' ) as file:
reader = csv.reader(file)
for row in reader:
print (row)
import pandas as pd
data = pd.read_csv('weight.csv' )
print (data.head())
課堂練習(綜合挑戰)
到現在,我們其實可以順道學習透過 streamlit 無痛的建立小專案
簡單的網路應用長什麼樣子?
> pip install streamlit
> streamlit hello
有興趣網站應用開發者,可參考之前課程
Data in Data Science
Strucutred and unstructured data
我們上面的課堂練習,對於結構性資料處理,已經稍微有一點小雛形了。
所謂有結構的資料,可以用結構化的方式來儲存,例如表格、關聯式資料庫等。
非結構性的資料,如文本,就涉及另一個大坑。Text analytics/Mining/NLP。
學習與輔助資源
請善用限時教育版的 datacamp, 你一定會升級!
其他免費的高品質學習資源還有:freecodecamp 及 Coursera
透過 chatGPT與 Github copilot X 來學習程式語言的語法,並且練習自己先寫程式。(也可讓 AI 家教幫你出題再練習)。
條件判斷與分支敘述 `if`, `for`, `while`
---
- Expressions(表達式):
- x > 10
- x == 10
- print("x is greater than 10"):print 函數調用也是一個表達式(因為它返回一個值,即 None,儘管我們這裡沒有使用返回值)。
- print("x is 10") 和 print("x is less than 10") 同理。
- Statements(陳述式) 包括:
- x = 15:一個賦值語句。
if x > 10::一個條件語句。
print("x is greater than 10"):一個語句(儘管 print 函數的調用也是一個表達式,但整行代碼進行了一個動作,所以它是一個語句)。
elif x == 10::一個條件語句。
print("x is 10"):同上。
else::一個條件語句。
print("x is less than 10"):同上。
---
# More on Data Type
- 「經匯率調整後,敝公司績效最佳的全球型基金在過去九年中有七年優於大盤」
*<p class="small-text">(*收益表現的調整方式究竟是什麼?這家公司有幾檔基金表現不如大盤?差多少?九年中有七年表現優於大盤的是同一檔基金嗎?或者好幾檔不同基金在那七年中各有一年獲得優於大盤的表現呢*)</p>
```
# 我們的學生分數數據
scores = {
'Alice': 95,
'Bob': 78,
'Charlie': 82,
'David': 60,
'Eva': 55,
'Frank': 92,
'Grace': 89,
'Henry': 97
}
# 初始化一些變數來儲存我們的結果
total_score = 0 # 總分數
failing_students = [] # 不及格的學生列表
excellent_students = [] # 優秀的學生列表
# 使用 for 迴圈遍歷每個學生的體重
for student, score in scores.items():
total_score += score # 將分數加到總分數中
# 使用 if 判斷來檢查學生的分數
if score < 60:
failing_students.append(student)
elif score >= 90:
excellent_students.append(student)
# 計算平均分數
average_score = total_score / len(scores)
(average_score, failing_students, excellent_students) # 顯示結果
```
---
## 名次排序問題
> 假定有一個由 M 個人所組成委員會,每個委員都分別針對 N 位候選人作出排序 (1-N 名)。最後要如何才能得到最合理的一個排名順序?可以介紹不同的演算法,並說明其優缺點。
- `Borda count method`
- 運作方式:給每個候選人根據他們在每個選民的排名中分配點數(例如,對於 N 個候選人,第一名得到 N 點,第二名得到 N-1 點,依此類推)。然後加總所有選民給予每位候選人的點數。
---
## 思考步驟
- 讀取 CSV:使用者上傳包含投票數據的 CSV 文件。
- 處理數據:解析上傳的數據並將其整理成方便處理的格式。
- 選擇算法:允許用戶選擇要使用的排名算法。
- 計算排名:使用選擇的算法計算候選人的排名。
- 顯示結果:以表格和/或圖表的形式顯示排名結果。
[範例 voting.py]()
```python
> streamlit run voting.py
```
---
# 資料型別 Data types
---
## 內建 (built-in)
- 基本資料型別(primitive data types)
- 複合資料型別 (composite Data Types)
- 特殊型別: NoneType: 有一個值 None,表示缺少值或空值。
## 第三方 (in third-party packages)
- `DataFrame` in **Pandas**
- `ndarray` in **Numpy**
---
## 內建基本資料型別
- int (整數): 例如 1, 100, -33 等。
- float (浮點數): 例如 1.0, 3.14, -0.001 等。
- str (字串): 例如 "Hello", 'Python' 等。
- bool (布林): 只有兩個值 - True 和 False。
---
## 內建複合資料型別
- list (列表): 一個有序的元素集合,例如 [1, 2, 3] 或 ["apple", "banana", "cherry"]。
- tuple (元組): 類似於列表,但是元素不能修改,例如 (1, 2, 3)。
- set (集合): 一個無序且不重複的元素集合,例如 {1, 2, 3}。
- dict (字典): 一個存儲鍵值對的無序集合,例如 {"name": "John", "age": 30}。
---
- 特殊資料型別
- 空值 (None)
- 自訂資料型別
- 類別 (Classes)
可用 `type()` 函數來檢查資料型別
【[📱chatGPT](https://chat.openai.com/share/08f1604a-d596-4898-b38b-b45bd911d61a)】
---
# 變數 Variables
- 變數是用來儲存資料的容器。
- 變數的名稱可以是任何合法的識別字 (identifier)。
- 變數的命名規則:
- 只能包含字母、數字和底線 (A-z, 0-9, and _ ),不能包含空格。
- 不能以數字開頭。
- 不能使用保留字 (reserved words)。
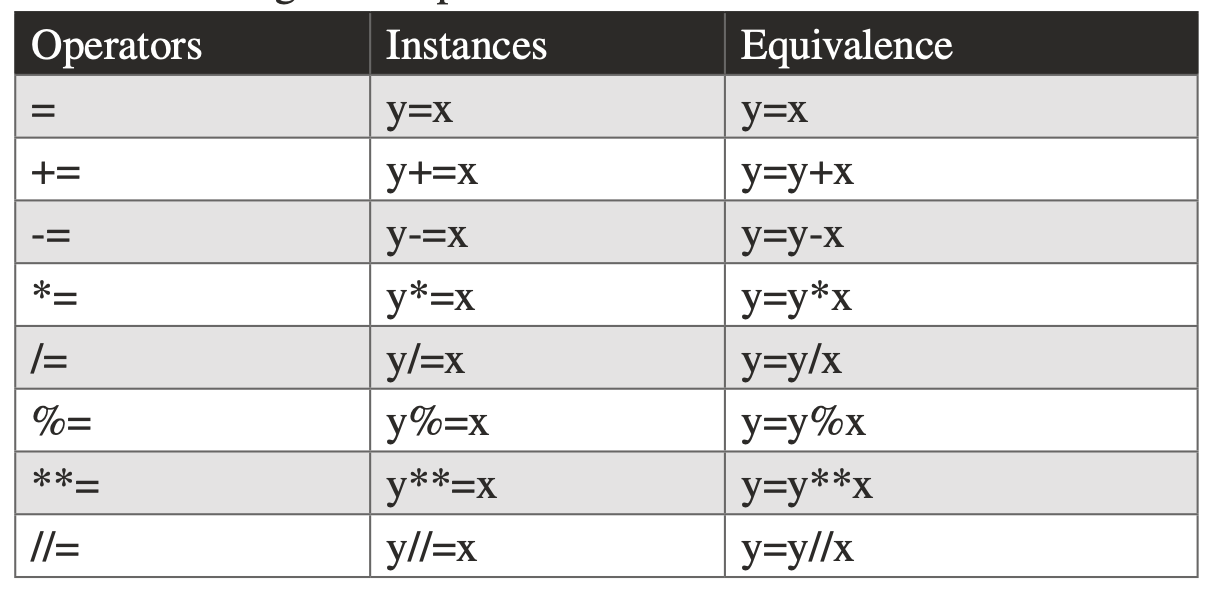
- 變數的給定,是用等號 `=` (assignment statement) 來指定。
---
# Operators and expressions
- 運算子 (operator) 是用來執行特定的任務。
- 運算元 (operand) 是運算子所作用的對象。
- 運算式 (expression) 是由運算子和運算元所組成的序列。
- 運算式的結果是一個值 (value)。
- 運算式的結果可以是一個物件 (object)。
---
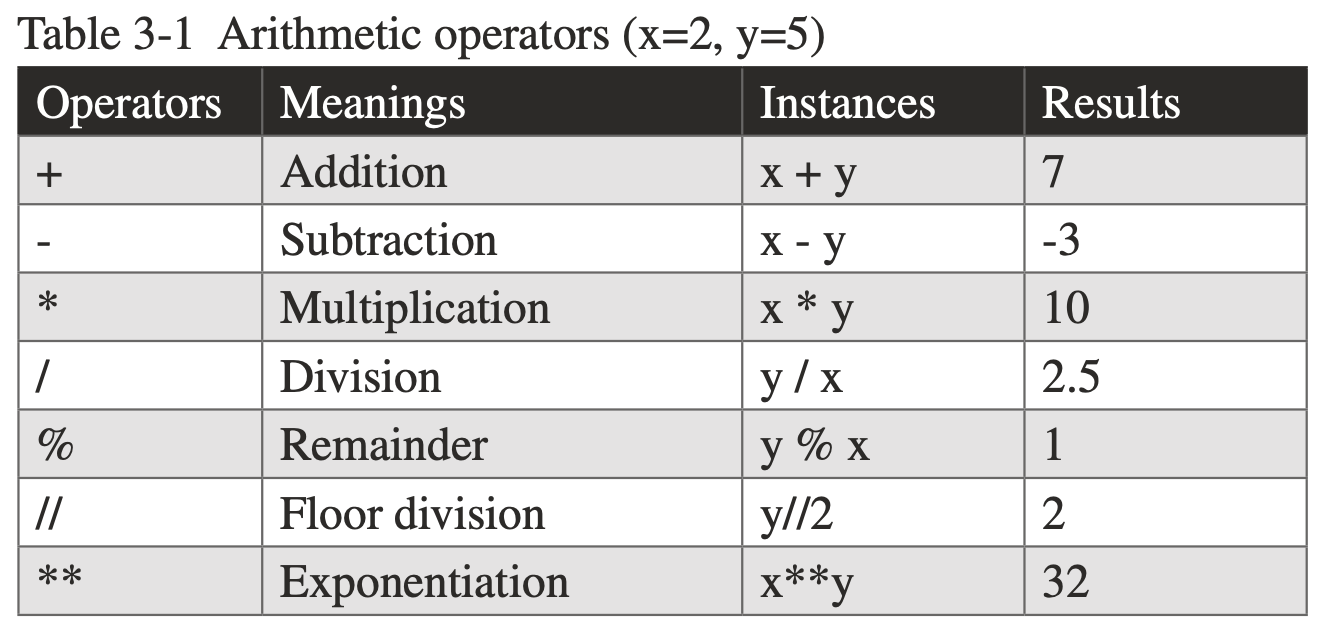
## Arithmetic operators
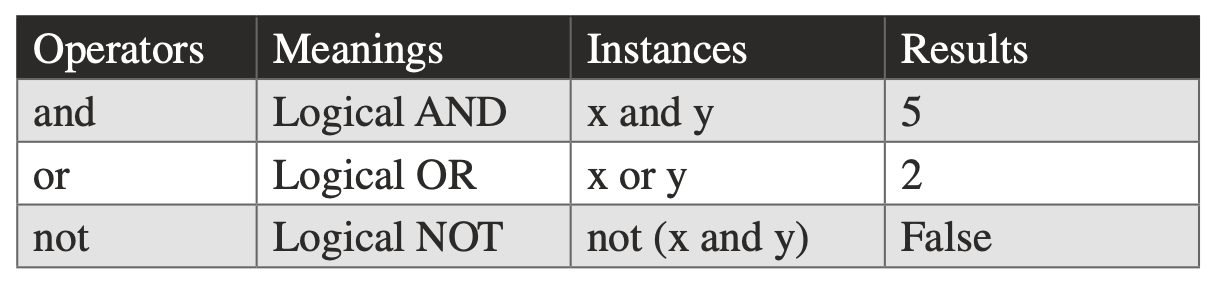
x =2, y = 5
---
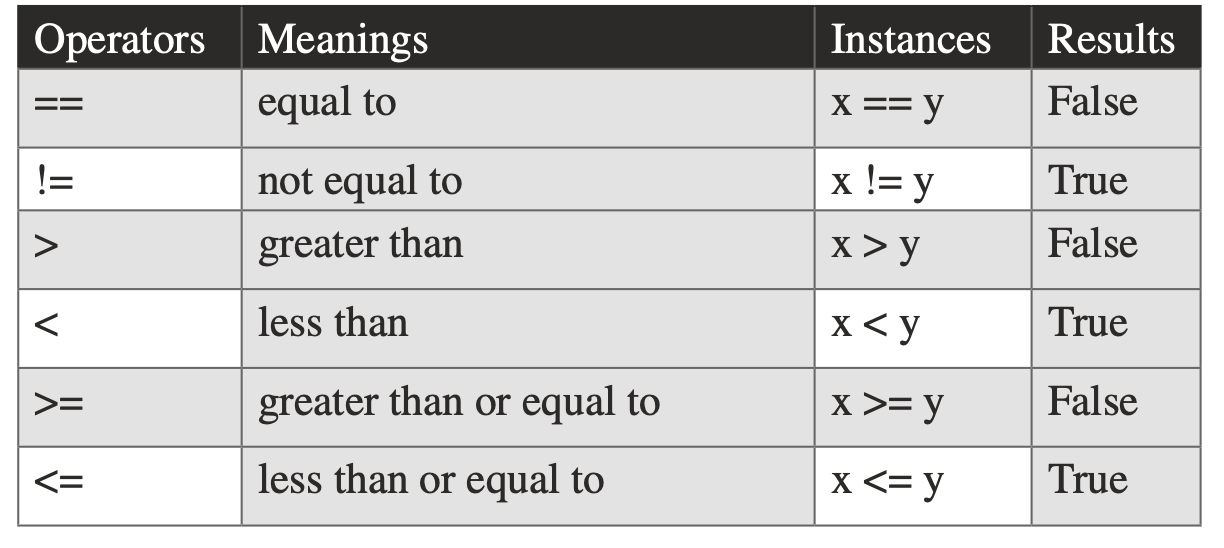
## Relational operators
---
## Assignment operators
---
## Logical operators
---
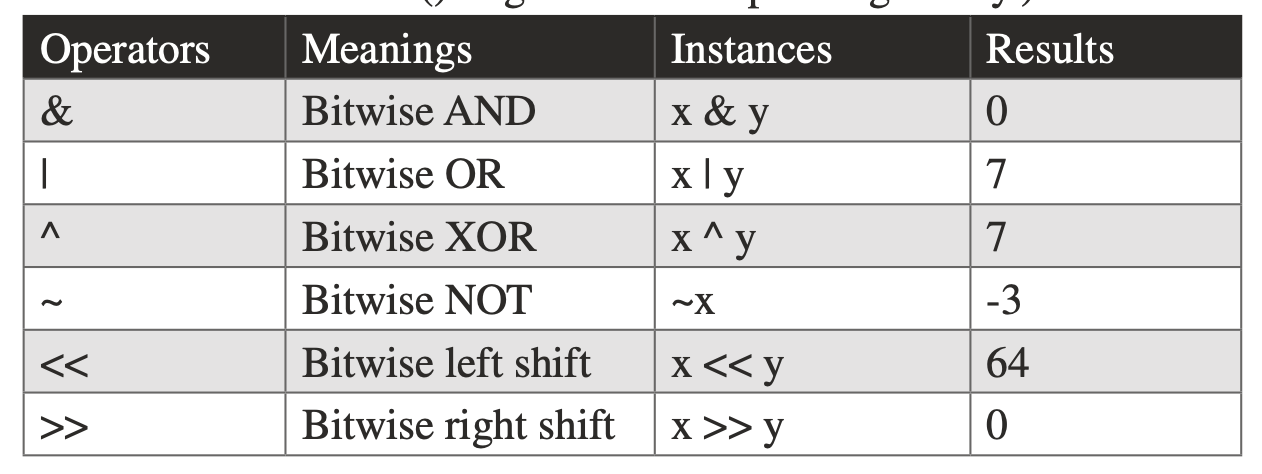
## Bitwise operators
x =2, y = 5 (use `bin()` to convert to binary)