lexicoR contains two lexical databases, DeepLex and Chinese Lexical Database. See the bottom of the page for Chinese Lexical Database’s original paper. All rights of the Chinese Lexical Database belong to the original authors.
Usage
library(lexicoR)The function, query.lu(), can be used to query lexical entries in these databases.
query.lu("我", regex = TRUE, isSimp = FALSE)
#> # A tibble: 652 x 300
#> lu_trad lu_simp cld.C1 cld.C123Backwar… cld.C123Backwar… cld.C123Conditi…
#> <chr> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 我 我 我 NA NA NA
#> 2 小我 小我 小 NA NA NA
#> 3 外我 外我 <NA> NA NA NA
#> 4 讀我 读我 <NA> NA NA NA
#> 5 敵我 敌我 敌 NA NA NA
#> 6 我輩 我辈 <NA> NA NA NA
#> 7 我軍 我军 我 NA NA NA
#> 8 我相 我相 <NA> NA NA NA
#> 9 我倆 我俩 <NA> NA NA NA
#> 10 給我 给我 <NA> NA NA NA
#> # … with 642 more rows, and 294 more variables: cld.C123Entropy <dbl>,
#> # cld.C12BackwardConditionalProbability <dbl>, cld.C12BackwardEntropy <dbl>,
#> # cld.C12ConditionalProbability <dbl>, cld.C12Entropy <dbl>,
#> # cld.C1BackwardConditionalProbability <dbl>, cld.C1BackwardEntropy <dbl>,
#> # cld.C1ConditionalProbability <dbl>, cld.C1Entropy <dbl>,
#> # cld.C1FamilyFrequency <dbl>, cld.C1FamilySize <int>, cld.C1Frequency <dbl>,
#> # cld.C1FrequencyRaw <int>, cld.C1FrequencyRawSUBTL <int>,
#> # cld.C1FrequencyRawWeibo <int>, cld.C1FrequencySUBTL <dbl>,
#> # cld.C1FrequencyWeibo <dbl>, cld.C1Friends <int>,
#> # cld.C1FriendsFrequency <dbl>, cld.C1HomographsFrequency <dbl>,
#> # cld.C1HomographTokens <int>, cld.C1HomographTypes <int>,
#> # cld.C1HomophonesFrequency <dbl>, cld.C1HomophoneTokens <int>,
#> # cld.C1HomophoneTypes <int>, cld.C1InitialDiphoneFrequency <dbl>,
#> # cld.C1InitialPhonemeFrequency <dbl>, cld.C1IPA <chr>,
#> # cld.C1MaxDiphoneFrequency <dbl>, cld.C1MaxPhonemeFrequency <dbl>,
#> # cld.C1MeanDiphoneFrequency <dbl>, cld.C1MeanPhonemeFrequency <dbl>,
#> # cld.C1MinDiphoneFrequency <dbl>, cld.C1MinPhonemeFrequency <dbl>,
#> # cld.C1OLDPixels <dbl>, cld.C1Phonemes <int>,
#> # cld.C1PhonologicalFrequency <dbl>, cld.C1PhonologicalN <int>,
#> # cld.C1PictureSize <int>, cld.C1Pinyin <chr>, cld.C1Pixels <int>,
#> # cld.C1PLD <dbl>, cld.C1PR <chr>, cld.C1PRBackwardEnemiesFrequency <dbl>,
#> # cld.C1PRBackwardEnemiesTokens <int>, cld.C1PRBackwardEnemiesTypes <int>,
#> # cld.C1PREnemiesFrequency <dbl>, cld.C1PREnemiesTokens <int>,
#> # cld.C1PREnemiesTypes <int>, cld.C1PRFamilySize <int>,
#> # cld.C1PRFrequency <dbl>, cld.C1PRFriends <int>,
#> # cld.C1PRFriendsFrequency <dbl>, cld.C1PRPinyin <chr>,
#> # cld.C1PRRegularity <int>, cld.C1PRStrokes <int>, cld.C1RE <dbl>,
#> # cld.C1SR <chr>, cld.C1SRFamilySize <int>, cld.C1SRFrequency <dbl>,
#> # cld.C1SRStrokes <int>, cld.C1Strokes <int>, cld.C1Structure <fct>,
#> # cld.C1Tone <fct>, cld.C1Type <fct>, cld.C2 <chr>,
#> # cld.C2FamilyFrequency <dbl>, cld.C2FamilySize <int>, cld.C2Frequency <dbl>,
#> # cld.C2FrequencyRaw <int>, cld.C2FrequencyRawSUBTL <int>,
#> # cld.C2FrequencyRawWeibo <int>, cld.C2FrequencySUBTL <dbl>,
#> # cld.C2FrequencyWeibo <dbl>, cld.C2Friends <int>,
#> # cld.C2FriendsFrequency <dbl>, cld.C2HomographsFrequency <dbl>,
#> # cld.C2HomographTokens <int>, cld.C2HomographTypes <int>,
#> # cld.C2HomophonesFrequency <dbl>, cld.C2HomophoneTokens <int>,
#> # cld.C2HomophoneTypes <int>, cld.C2InitialDiphoneFrequency <dbl>,
#> # cld.C2InitialPhonemeFrequency <dbl>, cld.C2IPA <chr>,
#> # cld.C2MaxDiphoneFrequency <dbl>, cld.C2MaxPhonemeFrequency <dbl>,
#> # cld.C2MeanDiphoneFrequency <dbl>, cld.C2MeanPhonemeFrequency <dbl>,
#> # cld.C2MinDiphoneFrequency <dbl>, cld.C2MinPhonemeFrequency <dbl>,
#> # cld.C2OLDPixels <dbl>, cld.C2Phonemes <int>,
#> # cld.C2PhonologicalFrequency <dbl>, cld.C2PhonologicalN <int>,
#> # cld.C2PictureSize <int>, cld.C2Pinyin <chr>, cld.C2Pixels <int>,
#> # cld.C2PLD <dbl>, cld.C2PR <chr>, …By default, query.lu() queries both databases. If you only want results from a particular database, you can provide an additional argument db:
query.lu("我", regex = TRUE, db = "deeplex")
#> # A tibble: 642 x 300
#> lu_trad lu_simp cld.C1 cld.C123Backwar… cld.C123Backwar… cld.C123Conditi…
#> <chr> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 我 我 我 NA NA NA
#> 2 小我 小我 小 NA NA NA
#> 3 外我 外我 <NA> NA NA NA
#> 4 讀我 读我 <NA> NA NA NA
#> 5 敵我 敌我 敌 NA NA NA
#> 6 我輩 我辈 <NA> NA NA NA
#> 7 我軍 我军 我 NA NA NA
#> 8 我相 我相 <NA> NA NA NA
#> 9 我倆 我俩 <NA> NA NA NA
#> 10 給我 给我 <NA> NA NA NA
#> # … with 632 more rows, and 294 more variables: cld.C123Entropy <dbl>,
#> # cld.C12BackwardConditionalProbability <dbl>, cld.C12BackwardEntropy <dbl>,
#> # cld.C12ConditionalProbability <dbl>, cld.C12Entropy <dbl>,
#> # cld.C1BackwardConditionalProbability <dbl>, cld.C1BackwardEntropy <dbl>,
#> # cld.C1ConditionalProbability <dbl>, cld.C1Entropy <dbl>,
#> # cld.C1FamilyFrequency <dbl>, cld.C1FamilySize <int>, cld.C1Frequency <dbl>,
#> # cld.C1FrequencyRaw <int>, cld.C1FrequencyRawSUBTL <int>,
#> # cld.C1FrequencyRawWeibo <int>, cld.C1FrequencySUBTL <dbl>,
#> # cld.C1FrequencyWeibo <dbl>, cld.C1Friends <int>,
#> # cld.C1FriendsFrequency <dbl>, cld.C1HomographsFrequency <dbl>,
#> # cld.C1HomographTokens <int>, cld.C1HomographTypes <int>,
#> # cld.C1HomophonesFrequency <dbl>, cld.C1HomophoneTokens <int>,
#> # cld.C1HomophoneTypes <int>, cld.C1InitialDiphoneFrequency <dbl>,
#> # cld.C1InitialPhonemeFrequency <dbl>, cld.C1IPA <chr>,
#> # cld.C1MaxDiphoneFrequency <dbl>, cld.C1MaxPhonemeFrequency <dbl>,
#> # cld.C1MeanDiphoneFrequency <dbl>, cld.C1MeanPhonemeFrequency <dbl>,
#> # cld.C1MinDiphoneFrequency <dbl>, cld.C1MinPhonemeFrequency <dbl>,
#> # cld.C1OLDPixels <dbl>, cld.C1Phonemes <int>,
#> # cld.C1PhonologicalFrequency <dbl>, cld.C1PhonologicalN <int>,
#> # cld.C1PictureSize <int>, cld.C1Pinyin <chr>, cld.C1Pixels <int>,
#> # cld.C1PLD <dbl>, cld.C1PR <chr>, cld.C1PRBackwardEnemiesFrequency <dbl>,
#> # cld.C1PRBackwardEnemiesTokens <int>, cld.C1PRBackwardEnemiesTypes <int>,
#> # cld.C1PREnemiesFrequency <dbl>, cld.C1PREnemiesTokens <int>,
#> # cld.C1PREnemiesTypes <int>, cld.C1PRFamilySize <int>,
#> # cld.C1PRFrequency <dbl>, cld.C1PRFriends <int>,
#> # cld.C1PRFriendsFrequency <dbl>, cld.C1PRPinyin <chr>,
#> # cld.C1PRRegularity <int>, cld.C1PRStrokes <int>, cld.C1RE <dbl>,
#> # cld.C1SR <chr>, cld.C1SRFamilySize <int>, cld.C1SRFrequency <dbl>,
#> # cld.C1SRStrokes <int>, cld.C1Strokes <int>, cld.C1Structure <fct>,
#> # cld.C1Tone <fct>, cld.C1Type <fct>, cld.C2 <chr>,
#> # cld.C2FamilyFrequency <dbl>, cld.C2FamilySize <int>, cld.C2Frequency <dbl>,
#> # cld.C2FrequencyRaw <int>, cld.C2FrequencyRawSUBTL <int>,
#> # cld.C2FrequencyRawWeibo <int>, cld.C2FrequencySUBTL <dbl>,
#> # cld.C2FrequencyWeibo <dbl>, cld.C2Friends <int>,
#> # cld.C2FriendsFrequency <dbl>, cld.C2HomographsFrequency <dbl>,
#> # cld.C2HomographTokens <int>, cld.C2HomographTypes <int>,
#> # cld.C2HomophonesFrequency <dbl>, cld.C2HomophoneTokens <int>,
#> # cld.C2HomophoneTypes <int>, cld.C2InitialDiphoneFrequency <dbl>,
#> # cld.C2InitialPhonemeFrequency <dbl>, cld.C2IPA <chr>,
#> # cld.C2MaxDiphoneFrequency <dbl>, cld.C2MaxPhonemeFrequency <dbl>,
#> # cld.C2MeanDiphoneFrequency <dbl>, cld.C2MeanPhonemeFrequency <dbl>,
#> # cld.C2MinDiphoneFrequency <dbl>, cld.C2MinPhonemeFrequency <dbl>,
#> # cld.C2OLDPixels <dbl>, cld.C2Phonemes <int>,
#> # cld.C2PhonologicalFrequency <dbl>, cld.C2PhonologicalN <int>,
#> # cld.C2PictureSize <int>, cld.C2Pinyin <chr>, cld.C2Pixels <int>,
#> # cld.C2PLD <dbl>, cld.C2PR <chr>, …When calling query.lu() for the first time, the databases (deeplex & cld) would be loaded into the global environment. These databases are stored as regular data frames. You can access it directly:
str(cld)
#> 'data.frame': 50549 obs. of 299 variables:
#> $ lu_trad : chr "中東" "馬隊" "門徒" "申討" ...
#> $ lu_simp : chr "中东" "马队" "门徒" "申讨" ...
#> $ cld.C1 : chr "中" "马" "门" "申" ...
#> $ cld.C123BackwardConditionalProbability: num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C123BackwardEntropy : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C123ConditionalProbability : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C123Entropy : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C12BackwardConditionalProbability : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C12BackwardEntropy : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C12ConditionalProbability : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C12Entropy : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C1BackwardConditionalProbability : num 0.043024 0.000951 0.25563 0.002027 NA ...
#> $ cld.C1BackwardEntropy : num 2.8 3.56 3.37 2.16 NA ...
#> $ cld.C1ConditionalProbability : num 0.003038 0.000725 0.087427 0.000572 NA ...
#> $ cld.C1Entropy : num 3.933 2.036 3.643 0.722 NA ...
#> $ cld.C1FamilyFrequency : num 1408.6 471.3 724 56.2 188.3 ...
#> $ cld.C1FamilySize : int 245 171 195 18 66 66 66 66 103 3 ...
#> $ cld.C1Frequency : num 2433 762 671 74 184 ...
#> $ cld.C1FrequencyRaw : int 492621 154252 135973 14987 37187 37187 37187 37187 104370 69 ...
#> $ cld.C1FrequencyRawSUBTL : int 69745 34892 25908 2358 5121 5121 5121 5121 13220 15 ...
#> $ cld.C1FrequencyRawWeibo : int 422876 119360 110065 12629 32066 32066 32066 32066 91150 54 ...
#> $ cld.C1FrequencySUBTL : num 1490.3 745.6 553.6 50.4 109.4 ...
#> $ cld.C1FrequencyWeibo : num 2716 766.6 706.9 81.1 205.9 ...
#> $ cld.C1Friends : int 223 171 194 18 46 46 46 46 103 2 ...
#> $ cld.C1FriendsFrequency : num 3187 570 856 58 153 ...
#> $ cld.C1HomographsFrequency : num 135.33 1.394 0.563 0 36.257 ...
#> $ cld.C1HomographTokens : int 22 1 1 0 22 22 22 22 0 0 ...
#> $ cld.C1HomographTypes : int 1 1 1 0 1 1 1 1 0 0 ...
#> $ cld.C1HomophonesFrequency : num 1606 285 48 2176 1398 ...
#> $ cld.C1HomophoneTokens : int 116 37 3 289 94 94 94 94 4 0 ...
#> $ cld.C1HomophoneTypes : int 5 5 1 9 3 3 3 3 2 0 ...
#> $ cld.C1InitialDiphoneFrequency : num 7635 10522 10153 14074 7703 ...
#> $ cld.C1InitialPhonemeFrequency : num 62190 51733 51733 89637 36220 ...
#> $ cld.C1IPA : chr "ʈʂʊŋ1" "ma3" "mən2" "ʂən1" ...
#> $ cld.C1MaxDiphoneFrequency : num 30825 10522 59561 59561 7703 ...
#> $ cld.C1MaxPhonemeFrequency : num 149471 321279 231563 231563 36220 ...
#> $ cld.C1MeanDiphoneFrequency : num 19230 10522 34857 36818 7703 ...
#> $ cld.C1MeanPhonemeFrequency : num 80829 186506 124276 136911 31644 ...
#> $ cld.C1MinDiphoneFrequency : num 7635 10522 10153 14074 7703 ...
#> $ cld.C1MinPhonemeFrequency : num 30825 51733 51733 89533 27067 ...
#> $ cld.C1OLDPixels : num 2002 2602 1875 2081 2438 ...
#> $ cld.C1Phonemes : int 3 2 3 3 2 2 2 2 3 3 ...
#> $ cld.C1PhonologicalFrequency : num 4796 856 913 2234 1582 ...
#> $ cld.C1PhonologicalN : int 15 21 15 15 9 9 9 9 6 24 ...
#> $ cld.C1PictureSize : int 1058 1875 1515 1225 1245 1245 1245 1245 2737 3726 ...
#> $ cld.C1Pinyin : chr "zhong1" "ma3" "men2" "shen1" ...
#> $ cld.C1Pixels : int 2623 2835 2160 3379 3641 3641 3641 3641 3975 4548 ...
#> $ cld.C1PLD : num 1.25 1 1.25 1.2 1.5 1.5 1.5 1.5 1.65 1 ...
#> $ cld.C1PR : chr NA NA NA NA ...
#> $ cld.C1PRBackwardEnemiesFrequency : num NA NA NA NA NA NA NA NA NA 0 ...
#> $ cld.C1PRBackwardEnemiesTokens : int NA NA NA NA NA NA NA NA NA 0 ...
#> $ cld.C1PRBackwardEnemiesTypes : int NA NA NA NA NA NA NA NA NA 0 ...
#> $ cld.C1PREnemiesFrequency : num NA NA NA NA NA NA NA NA NA 0 ...
#> $ cld.C1PREnemiesTokens : int NA NA NA NA NA NA NA NA NA 0 ...
#> $ cld.C1PREnemiesTypes : int NA NA NA NA NA NA NA NA NA 0 ...
#> $ cld.C1PRFamilySize : int NA NA NA NA NA NA NA NA NA 1 ...
#> $ cld.C1PRFrequency : num NA NA NA NA NA ...
#> $ cld.C1PRFriends : int NA NA NA NA NA NA NA NA NA 2 ...
#> $ cld.C1PRFriendsFrequency : num NA NA NA NA NA ...
#> $ cld.C1PRPinyin : chr NA NA NA NA ...
#> $ cld.C1PRRegularity : int NA NA NA NA NA NA NA NA NA 0 ...
#> $ cld.C1PRStrokes : int NA NA NA NA NA NA NA NA NA 12 ...
#> $ cld.C1RE : num 5.2 5.44 4.31 4.88 NA ...
#> $ cld.C1SR : chr "丨" "马" "门" "田" ...
#> $ cld.C1SRFamilySize : int 6 34 28 22 9 9 9 9 10 56 ...
#> $ cld.C1SRFrequency : num 10275 1869 3882 4157 4287 ...
#> $ cld.C1SRStrokes : int 1 3 3 5 4 4 4 4 12 6 ...
#> $ cld.C1Strokes : int 4 3 3 5 6 6 6 6 12 18 ...
#> $ cld.C1Structure : Factor w/ 6 levels "CIR","HCI","LR",..: 5 5 5 5 5 5 5 5 6 6 ...
#> $ cld.C1Tone : Factor w/ 5 levels "1","2","3","4",..: 1 3 2 1 3 3 3 3 1 1 ...
#> $ cld.C1Type : Factor w/ 5 levels "Other","PicLog",..: 2 5 5 2 5 5 5 5 4 3 ...
#> $ cld.C2 : chr "东" "队" "徒" "讨" ...
#> $ cld.C2FamilyFrequency : num 979 315 66 288 NA ...
#> $ cld.C2FamilySize : int 101 105 37 25 NA NA NA NA 34 699 ...
#> $ cld.C2Frequency : num 805.9 286.7 51.8 209.7 NA ...
#> $ cld.C2FrequencyRaw : int 163202 58066 10498 42457 NA NA NA NA 10718 664892 ...
#> $ cld.C2FrequencyRawSUBTL : int 44037 27111 3604 10151 NA NA NA NA 2997 177693 ...
#> $ cld.C2FrequencyRawWeibo : int 119165 30955 6894 32306 NA NA NA NA 7721 487199 ...
#> $ cld.C2FrequencySUBTL : num 941 579 77 217 NA ...
#> $ cld.C2FrequencyWeibo : num 765.4 198.8 44.3 207.5 NA ...
#> $ cld.C2Friends : int 101 105 37 25 NA NA NA NA 33 515 ...
#> $ cld.C2FriendsFrequency : num 1017.5 388.2 57.9 298.6 NA ...
#> $ cld.C2HomographsFrequency : num 0 0 0 0 NA ...
#> $ cld.C2HomographTokens : int 0 0 0 0 NA NA NA NA 2 185 ...
#> $ cld.C2HomographTypes : int 0 0 0 0 NA NA NA NA 1 1 ...
#> $ cld.C2HomophonesFrequency : num 300 3485 1221 0 NA ...
#> $ cld.C2HomophoneTokens : int 47 122 147 0 NA NA NA NA 274 1 ...
#> $ cld.C2HomophoneTypes : int 4 3 5 0 NA NA NA NA 5 1 ...
#> $ cld.C2InitialDiphoneFrequency : num 3881 9448 2020 16354 NA ...
#> $ cld.C2InitialPhonemeFrequency : num 122891 122891 42095 42095 NA ...
#> $ cld.C2IPA : chr "tʊŋ1" "twei4" "tʰu2" "tʰau3" ...
#> $ cld.C2MaxDiphoneFrequency : num 30825 60592 2020 70492 NA ...
#> $ cld.C2MaxPhonemeFrequency : num 149471 283816 192765 321279 NA ...
#> $ cld.C2MeanDiphoneFrequency : num 17353 36106 2020 43423 NA ...
#> $ cld.C2MeanPhonemeFrequency : num 101062 165116 117430 185380 NA ...
#> $ cld.C2MinDiphoneFrequency : num 3881 9448 2020 16354 NA ...
#> $ cld.C2MinPhonemeFrequency : num 30825 91491 42095 42095 NA ...
#> $ cld.C2OLDPixels : num 2387 2521 2478 2241 NA ...
#> $ cld.C2Phonemes : int 3 4 2 3 NA NA NA NA 3 2 ...
#> [list output truncated]str(deeplex)
#> 'data.frame': 317699 obs. of 300 variables:
#> $ lu_trad : chr "節" "筋" "破" "祈" ...
#> $ lu_simp : chr "节" "筋" "破" "祈" ...
#> $ cld.C1 : chr "节" "筋" "破" "祈" ...
#> $ cld.C123BackwardConditionalProbability: num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C123BackwardEntropy : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C123ConditionalProbability : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C123Entropy : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C12BackwardConditionalProbability : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C12BackwardEntropy : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C12ConditionalProbability : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C12Entropy : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C1BackwardConditionalProbability : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C1BackwardEntropy : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C1ConditionalProbability : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C1Entropy : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C1FamilyFrequency : num 901 25.8 183.7 66.9 308.5 ...
#> $ cld.C1FamilySize : int 98 16 75 6 24 56 34 9 26 309 ...
#> $ cld.C1Frequency : num 664.2 26.2 208.8 48 245.5 ...
#> $ cld.C1FrequencyRaw : int 134503 5311 42283 9724 49720 71606 330995 5221 15582 546473 ...
#> $ cld.C1FrequencyRawSUBTL : int 17377 728 10541 2293 9589 6381 50512 990 1386 87630 ...
#> $ cld.C1FrequencyRawWeibo : int 117126 4583 31742 7431 40131 65225 280483 4231 14196 458843 ...
#> $ cld.C1FrequencySUBTL : num 371.3 15.6 225.2 49 204.9 ...
#> $ cld.C1FrequencyWeibo : num 752.3 29.4 203.9 47.7 257.7 ...
#> $ cld.C1Friends : int 97 16 76 6 24 57 34 8 26 58 ...
#> $ cld.C1FriendsFrequency : num 900.5 25.8 183.8 66.9 308.5 ...
#> $ cld.C1HomographsFrequency : num 0.467 0 0 0 0 ...
#> $ cld.C1HomographTokens : int 1 0 0 0 0 0 0 3 0 251 ...
#> $ cld.C1HomographTypes : int 1 0 0 0 0 0 0 2 0 1 ...
#> $ cld.C1HomophonesFrequency : num 1425.6 4065.2 91.4 1660.9 499.9 ...
#> $ cld.C1HomophoneTokens : int 220 299 33 251 103 15 30 0 8 2 ...
#> $ cld.C1HomophoneTypes : int 14 9 4 21 11 2 6 0 4 1 ...
#> $ cld.C1InitialDiphoneFrequency : num 39133 26485 687 17006 33764 ...
#> $ cld.C1InitialPhonemeFrequency : num 71647 71647 13649 36220 283816 ...
#> $ cld.C1IPA : chr "tɕje2" "tɕin1" "pʰwo4" "tɕʰi2" ...
#> $ cld.C1MaxDiphoneFrequency : num 39133 26542 81826 17006 33764 ...
#> $ cld.C1MaxPhonemeFrequency : num 175419 283816 162267 283816 283816 ...
#> $ cld.C1MeanDiphoneFrequency : num 26879 26514 41256 17006 33764 ...
#> $ cld.C1MeanPhonemeFrequency : num 112852 195675 106842 160018 216643 ...
#> $ cld.C1MinDiphoneFrequency : num 14624 26485 687 17006 33764 ...
#> $ cld.C1MinPhonemeFrequency : num 71647 71647 13649 36220 149471 ...
#> $ cld.C1OLDPixels : num 2560 2895 2563 2461 2384 ...
#> $ cld.C1Phonemes : int 3 3 3 2 2 4 3 4 3 2 ...
#> $ cld.C1PhonologicalFrequency : num 2372 4092 360 1728 857 ...
#> $ cld.C1PhonologicalN : int 10 9 17 15 6 8 24 9 13 18 ...
#> $ cld.C1PictureSize : int 1693 3720 3730 3372 3069 3840 3145 2612 3639 3577 ...
#> $ cld.C1Pinyin : chr "jie2" "jin1" "po4" "qi2" ...
#> $ cld.C1Pixels : int 2801 4279 4103 3286 3682 3590 4077 3803 4153 3352 ...
#> $ cld.C1PLD : num 1.5 1.45 1.1 1.1 1.3 1.45 1 1.4 1.35 1 ...
#> $ cld.C1PR : chr "卩" NA "皮" "斤" ...
#> $ cld.C1PRBackwardEnemiesFrequency : num 1322.36 NA 91.4 575.95 1.52 ...
#> $ cld.C1PRBackwardEnemiesTokens : int 166 NA 33 150 10 NA 23 0 5 NA ...
#> $ cld.C1PRBackwardEnemiesTypes : int 9 NA 3 23 4 NA 4 1 4 NA ...
#> $ cld.C1PREnemiesFrequency : num 233.8 NA 2120.4 3905.6 69.4 ...
#> $ cld.C1PREnemiesTokens : int 33 NA 154 258 36 NA 14 15 0 NA ...
#> $ cld.C1PREnemiesTypes : int 4 NA 8 6 2 NA 2 3 0 NA ...
#> $ cld.C1PRFamilySize : int 4 NA 11 8 3 NA 5 4 3 NA ...
#> $ cld.C1PRFrequency : num 824 NA 1763 2764 306 ...
#> $ cld.C1PRFriends : int 97 NA 76 7 24 NA 41 8 29 NA ...
#> $ cld.C1PRFriendsFrequency : num 900.5 NA 183.8 66.9 308.5 ...
#> $ cld.C1PRPinyin : chr "jie2" NA "pi2" "jin1" ...
#> $ cld.C1PRRegularity : int 1 NA 0 0 0 NA 0 0 0 NA ...
#> $ cld.C1PRStrokes : int 2 NA 5 4 4 NA 7 6 8 NA ...
#> $ cld.C1RE : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C1SR : chr "艹" "⺮" "石" "礻" ...
#> $ cld.C1SRFamilySize : int 191 56 61 25 81 15 72 72 39 15 ...
#> $ cld.C1SRFrequency : num 9165 5915 1851 4131 28384 ...
#> $ cld.C1SRStrokes : int 3 6 5 5 3 2 4 4 3 2 ...
#> $ cld.C1Strokes : int 5 12 10 9 7 4 11 10 11 5 ...
#> $ cld.C1Structure : Factor w/ 6 levels "CIR","HCI","LR",..: 6 6 3 3 4 3 3 6 3 5 ...
#> $ cld.C1Tone : Factor w/ 5 levels "1","2","3","4",..: 2 1 4 2 2 1 3 4 3 4 ...
#> $ cld.C1Type : Factor w/ 5 levels "Other","PicLog",..: 3 4 3 3 3 4 3 3 3 1 ...
#> $ cld.C2 : chr NA NA NA NA ...
#> $ cld.C2FamilyFrequency : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2FamilySize : int NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2Frequency : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2FrequencyRaw : int NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2FrequencyRawSUBTL : int NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2FrequencyRawWeibo : int NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2FrequencySUBTL : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2FrequencyWeibo : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2Friends : int NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2FriendsFrequency : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2HomographsFrequency : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2HomographTokens : int NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2HomographTypes : int NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2HomophonesFrequency : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2HomophoneTokens : int NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2HomophoneTypes : int NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2InitialDiphoneFrequency : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2InitialPhonemeFrequency : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2IPA : chr NA NA NA NA ...
#> $ cld.C2MaxDiphoneFrequency : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2MaxPhonemeFrequency : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2MeanDiphoneFrequency : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2MeanPhonemeFrequency : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2MinDiphoneFrequency : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2MinPhonemeFrequency : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2OLDPixels : num NA NA NA NA NA NA NA NA NA NA ...
#> $ cld.C2Phonemes : int NA NA NA NA NA NA NA NA NA NA ...
#> [list output truncated]
Lexical databases in lexicoR
The two databases, deeplex & cld, were preprocessed and left-joined together respectively, before being bundled to the package. Hence, they have identical variables, with the source database’s name (cld., cwn., or dl.) prepended to the variables’ names.
The variable cwn.n_sense records the number of senses of a lemma that can be found in Chinese Wordnet. There are only about 4,500 lemmas in Chinese Wordnet, which is few compared to DeepLex and Chinese Lexical Database, hence many entries in cwn.n_sense are NA. The venn diagram below shows the number of overlapping and distinct lexical entries found in the three lexical databases.
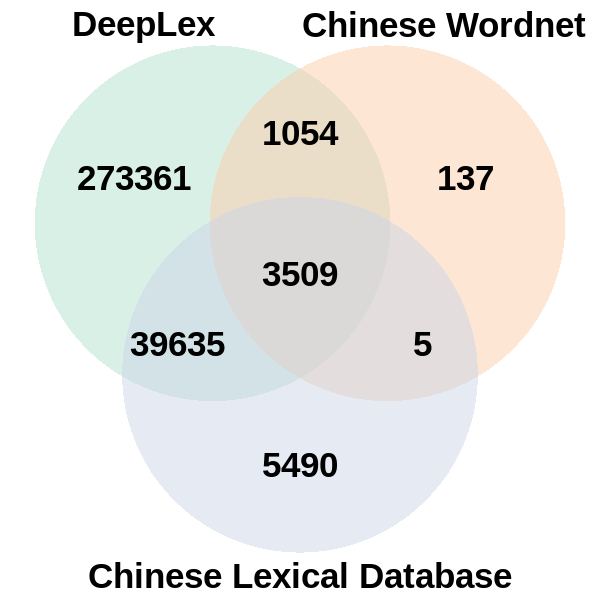
The numbers of overlapping and distinct lexical entries in DeepLex, Chinese Lexical Database, and Chinese Wordnet
References
Sun, C. C., Hendrix, P., Ma, J.Q. & Baayen, R. H. (2018). Chinese Lexical Database (CLD): A large-scale lexical database for simplified Mandarin Chinese. Behavior Research Methods, https://doi.org/10.3758/s13428-018-1038-3.