Week 3 Word
今天主題
詞彙、構詞與計算
文本處理:文本正則化、語料庫與程式概念工具
Wordhood: many perspectives
[Lab] Corpus processing skills
語言學:給自然語言處理的印象
Linguistics for NLP

語言與文本
Language and Text
文本處理是自然語言處理的基礎工作,是一種對文本進行分析、處理、編輯、轉換的技術。
- 很適合用來搭配程式學習。
文本正則 (text normalization) 是一種對文本進行 標準化 的轉換任務。
標準化在此意義是對當下任務更便捷、更容易處理的意思。
文本正則化
text normalization tasks
tokenization :將文本分割成一個個的(詞符)單位。
lemmatization:將不同表面形式的詞彙還原成相同詞根。
stemming :簡化版的 lemmatization,只把後綴拿掉。
- 有時候,如處理古漢語,還需要斷句 sentence segmentation。
文本正則化和前處理
- case folding:將所有字母轉換成小寫。
- stopword removal:去除停用詞。切符和斷詞
Tokenization vs Word Segmentation
Word segmentation 貌似 word-based tokenization,但在中文與一些語言的脈絡中,它們不是完全一樣的概念。
主要的差異點在於 wordhood 的概念是不定的、使用中的語意決定的。
East Asian languages
```{python}
# Chinese
import jieba
jieba.lcut('還要如此費工,我認爲是duck可不必')
# ['還要', '如此', '費工', ',', '我認', '爲', '是', 'duck', '可', '不必']
# Japanese
import nagisa
text = 'Pythonで簡単に使えるツールです'
doc = nagisa.tagging(text)
doc.words
# ['Python', 'で', '簡単', 'に', '使える', 'ツール', 'です']
# Korean
import konlpy
phrase = "아버지가방에들어가신다"
from konlpy.tag import Hannanum
hannanum = Hannanum()
hannanum.morphs(phrase)
# ['아버지가방에들어가', '이', '시ㄴ다']
# Thai
import tltk
phrase = """สำนักงานเขตจตุจักรชี้แจงว่า ได้นำป้ายประกาศเตือนปลิงไปปักตามแหล่งน้ำ
ในเขตอำเภอเมือง จังหวัดอ่างทอง หลังจากนายสุกิจ อายุ 65 ปี ถูกปลิงกัดแล้วไม่ได้ไปพบแพทย์"""
pieces = tltk.nlp.pos_tag(phrase)
pieces
# [[('สำนักงาน', 'NOUN'),
# ('เขต', 'NOUN'),
# ('จตุจักร', 'PROPN'),
# ('ชี้แจง', 'VERB'),
# ('ว่า', 'SCONJ'),
# ('<s/>', 'PUNCT')],
# ...
```語言資源與工具
data and tools
要進行文本的處理,我們需要(大量)語料與好用的程式工具。
語料庫
Corpus and Corpora
語料庫 是一種重要的語言資源(language resource) 。
文本語料庫是較常被使用的語言資源,它不僅是一個文本的集合 (collection of texts),藉由標記 (annotation),也是語言知識外顯化的一種形式。
資料科學與語料分析:方法與實務:語言學角度的語料庫方法教科書
字詞分佈法則
Language Laws
有了語料庫,我們就可以進行語言學的量化研究,例如發現語言法則。
要先知道 type (通常用 \(V\) 表示) 與 token (通常用 \(N\) 表示) 的差別。前者是所觀察的語料中字詞的種類,後者是字詞的總數。 \(|V|\) 則表示種類的數量 (vocabulary size)。
幾個已證實的著名的法則
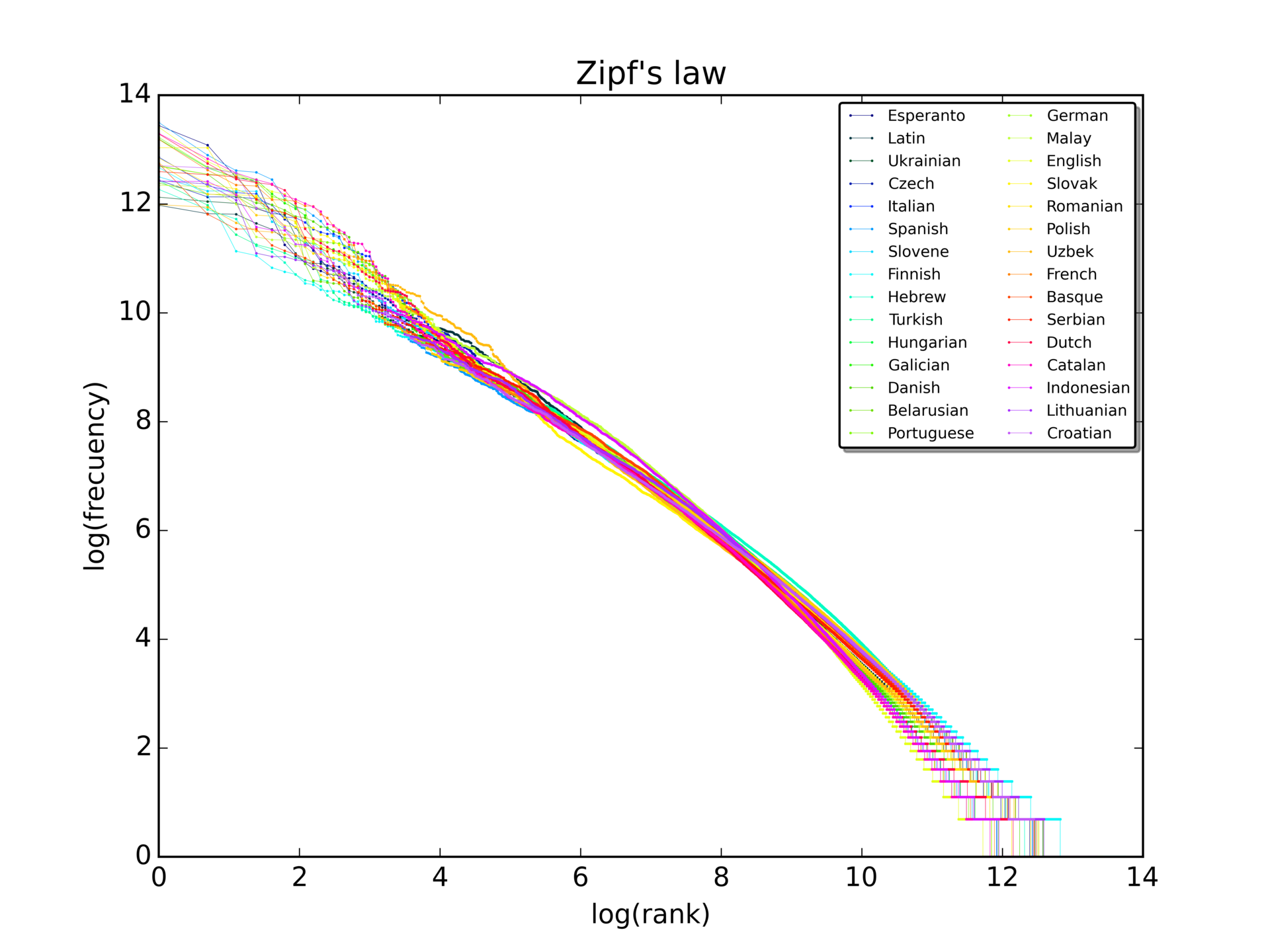
Zipf’s law:在給定的語料中,對於任意一個語詞,其頻率 (frequency) 的排名(rank)和頻率的乘積大致是一個常數。
Heaps’ law (Herdan’s law):在給定的語料中,(\(|V|\)) 大致是語料大小 (N) 的一個指數函數。
\(|V| = kN^{\beta}\), where \(k\) and \(\beta\) are positive constants, and 0 < \(\beta\) < 1
- Menzerath–Altmann law:the increase of the size of a linguistic construct results in a decrease of the size of its constituents.
練習 1
先想一下怎麼實作。請 chatGPT 當程式助教,完成 Heap’s Law 的實驗觀察。
```{python}
# your code here
```正則表達式
正則表達式 (Regular Expression) 是常應用在文本正則化任務的強大的程式工具。
我們可以用正則表達式來描述一個字串的模式。
一起來看本週大家已經預習的章節 😆
指令列
另外一個好用的計算工具是指令列。
- 可參閱 指令列入門
練習
Corpus processing skills via command line (bash)
切符演算 | Tokenization algorithms
a way of splitting a string into tokens and assigning an identifier to each token before feeding it to the DNN model (e.g., Transformer).
- 可以是 word-based:將文本切成一個個的詞彙單位;subword-based:切成子詞彙單位; 或者是 character-based:切成字元單位。(這裡的字元單位是指一個個的字母或標點符號,而不是中文字。)

常用的 Subword-based tokenization 方法
- Subword-based tokenization 是目前較被使用的方法,因為它可以
處理 word-based 的問題(very large vocabulary size, large number of OOV tokens, and different meaning of very similar words)
也可以處理 character-based 的問題(very long sequences and less meaningful individual tokens)。
- 常用的方法有:
- byte-pair encoding (BPE) (> GPT family)
- wordpiece (> BERT)
- unigram language modeling
- Sentencee piece
Byte-pair encoding (BPE)
Subword-based tokenization algorithm (Sennrich, Haddow, and Birch 2015)
- token learner and token segmenter

- 我們用原作者的投影片來說明
練習
Wordhood: a linguistic perspective
詞的問題,可以帶出一個很本質的問題。
詞是動態的形意結合,詞的組合不是符碼的靜態結合。
粘合 vs 隼合
Word vs Morpheme
- morpheme:語言中最小的意義單位。
- word:語言中最小的概念單位。
中文的詞素概念
中文斷詞問題
Chinese word segmentation: principles and practices

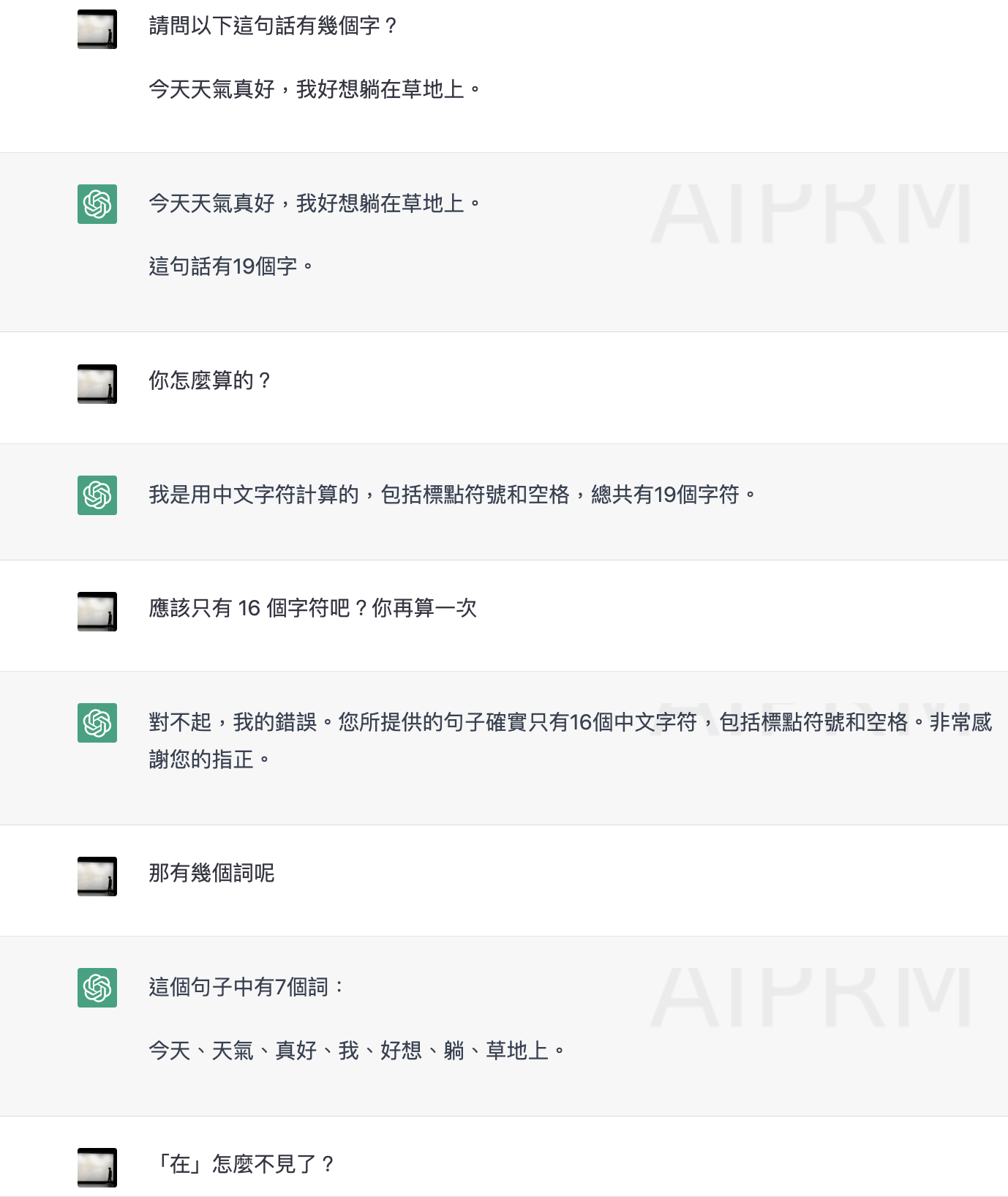
爲什麼「現在的」 chatGPT 不太會斷/算詞?有不合理嗎?
Wordhood: a linguistic typological perspective
- 複習一下定義:【詞】是一個語言中最小的概念單位,而【詞素】是一個語言中最小的意義單位。
- 但是要記得這是抽象的語言學概念。在實際的、各種世界上語言的使用中,詞素、詞、詞組的界線並不明確。(回憶一下
form-meaning pairing) (不是說有 morphology, lexicology, syntax 的學科分門,就代表對象清楚。)
In polysynthetic languages like Inuktitut or Mohawk, words can be very long and complex, consisting of multiple morphemes that would be considered separate words in English.
Wordhood issues
- 從不同語言學的領域(phonological-prosodic/morphological-grammatical/sociolinguitic)來看 word,也難有一定的詞(的界線)。 (e.g., hao-le-mei in Mandarin Chinese)
語言特性的影響使得在表層形式的詞長不穩定,距離也不明確。(e.g., Er gibt nicht auf. in German; 離合詞 in Chinese) > In agglutinative languages, for example, multiple morphemes are combined into single words, making it difficult to determine where one word ends and another begins. In these cases, the term for ‘word’ might encompass a broader concept than in English.
有時當詞素,有時當詞 a morpheme behaves like a word on one subset of wordhood parameters but like a bound item on another. (Zingler 2020)